На этом шаге мы рассмотрим, как влияет на процесс обучения увеличение мощности модели.
Если вам удалось найти подходящую модель, которая показывает постепенное уменьшение потерь и, кажется, достигает хотя бы некоторого уровня общности, поздравляем: вы почти у цели. Теперь вам нужно найти точку, когда наступает переобучение модели.
Рассмотрим следующую небольшую модель - простую логистическую регрессию, обученную на изображениях MNIST
Пример 5.9. Простая логистическая регрессия на наборе данных MNIST
from tensorflow.keras.datasets import mnist from tensorflow import keras from tensorflow.keras import layers (train_images, train_labels), _ = mnist.load_data() train_images = train_images.reshape((60000, 28 * 28)) train_images = train_images.astype("float32") / 255 model = keras.Sequential([layers.Dense(10, activation="softmax")]) model.compile(optimizer="rmsprop", loss="sparse_categorical_crossentropy", metrics=["accuracy"]) history_small_model = model.fit( train_images, train_labels, epochs=20, batch_size=128, validation_split=0.2)
По результатам обучения получилась кривая потерь, изображенная на рисунке 1:
import matplotlib.pyplot as plt val_loss = history_small_model.history["val_loss"] epochs = range(1, 21) plt.plot(epochs, val_loss, "b--", label="Потери на этапе проверки") plt.title("Эффект недостаточной емкости модели") plt.xlabel("Эпохи") plt.ylabel("Потери") plt.legend()
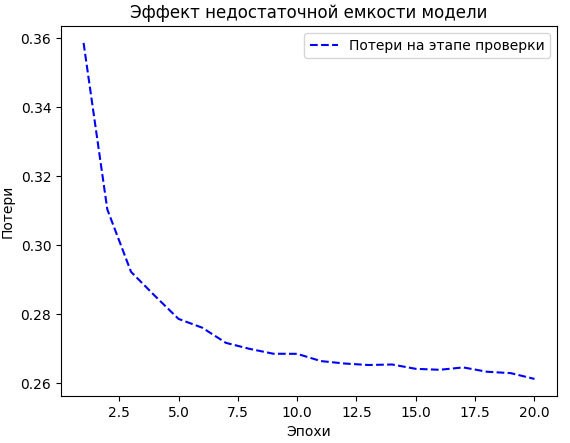
Рис.1. Эффект недостаточной емкости модели
Величина потерь на проверочных данных, кажется, остановилась или очень медленно улучшается - вместо того чтобы пойти вспять. Она достигла значения 0,26 и продолжает колебаться около него. Вы можете продолжать обучение, но эффект переобучения не наступает даже после множества итераций. Скорее всего, в своей карьере вы часто будете сталкиваться с подобными случаями.
Помните, что в любой задаче должно наступать переобучение. Равно как проблему неуменьшающихся потерь при обучении, данный вопрос также всегда можно решить. Если возникает ощущение, что переобучение не наступает, скорее всего, проблема связана с недостаточной репрезентативной мощностью вашей модели. Попробуйте сконструировать модель большего размера, с большей емкостью (то есть способную хранить больше информации). Повысить репрезентативную мощность можно, добавив больше слоев, используя более крупные слои (с большим количеством параметров) или типы слоев, лучше подходящие для данной задачи (более удачную архитектуру).
Попробуем обучить более крупную модель, состоящую из двух промежуточных слоев по 96 нейронов в каждом:
model = keras.Sequential([
layers.Dense(96, activation="relu"),
layers.Dense(96, activation="relu"),
layers.Dense(10, activation="softmax"),
])
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
history_large_model = model.fit(
train_images, train_labels,
epochs=20,
batch_size=128,
validation_split=0.2)
Кривая потерь на проверочных данных теперь выглядит так, как должна: модель быстро обучается, и через восемь эпох наступает эффект переобучения (рисунок 2).
val_loss = history_large_model.history["val_loss"] epochs = range(1, 21) plt.plot(epochs, val_loss, "b--", label="Потери на этапе проверки") plt.title("График кривой потерь для модели с достаточной емкостью") plt.xlabel("Эпохи") plt.ylabel("Потери") plt.legend()
Блокнот с этим примером можно взять здесь.
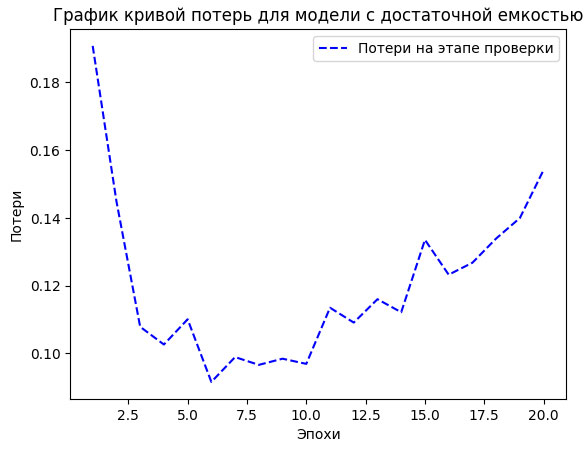
Рис.2. График кривой потерь для модели с достаточной емкостью
Со следующего шага мы займемся улучшением общности.
