На этом шаге мы рассмотрим особенности выполнения этой операции.
Причиной переобучения является недостаточное количество образцов для обучения модели, способной обобщать новые данные. Имея бесконечный объем данных, можно было бы получить модель, учитывающую все аспекты распределения данных: эффект переобучения никогда не наступил бы. Прием обогащения данных реализует подход создания дополнительных обучающих данных из имеющихся путем трансформации образцов множеством случайных преобразований, дающих правдоподобные изображения. Цель состоит в том, чтобы на этапе обучения модель никогда не увидела одно и то же изображение дважды. Это поможет модели выявить больше особенностей данных и достичь лучшей степени обобщения.
Сделать подобное в Keras можно путем добавления нескольких слоев обогащения данных в начале модели. Начнем с простого примера. Приведенная далее последовательная модель применяет несколько случайных преобразований к изображениям. Мы добавим ее в нашу модель прямо перед слоем Rescaling.
Пример 8.14. Определение этапа обогащения данных для добавления в модель
data_augmentation = keras.Sequential(
[
layers.RandomFlip("horizontal"),
layers.RandomRotation(0.1),
layers.RandomZoom(0.2),
]
)
Здесь представлена лишь часть возможных вариантов (полный список вы найдете в документации к фреймворку Keras). Давайте быстро пробежимся по этому коду:
- RandomFlip("horizontal") - переворачивает по горизонтали 50% случайно выбранных изображений;
- RandomRotation(0.1) - поворачивает входные изображения на случайный угол в диапазоне [-10%, +10%] (параметр определяет долю полной окружности - в градусах заданный здесь диапазон составит [-36, +36]);
- RandomZoom(0.2) - случайным образом изменяет масштаб изображения, в данном случае в диапазоне [-20%, +20%].
Давайте посмотрим, как выглядят дополнительные изображения (рисунок 1).

Рис.1. Варианты изображения с кошкой, полученные применением случайных преобразований
Пример 8.15. Отображение некоторых дополнительных обучающих изображений
plt.figure(figsize=(10, 10)) # take (N) позволяет выбрать только N пакетов из набора данных. # Этот метод действует подобно инструкции break, выполняемой циклом # после N-го пакетаВывести for images, _ in train_dataset.take(1): for i in range(9): # Применить этап обогащения к пакету изображений augmented_images = data_augmentation(images) ax = plt.subplot(3, 3, i + 1) # Вывести первое изображение в выходном пакете. Во всех девяти итерациях # будут получены дополнительные варианты, полученные обогащением одного # и того же изображения plt.imshow(augmented_images[0].numpy().astype("uint8")) plt.axis("off")
Если обучить новую модель с использованием этих обогащенных данных, она никогда не увидит одно и то же изображение дважды. Однако входные данные по-прежнему будут тесно связаны между собой, потому что получены из небольшого количества оригинальных изображений, - у вас не получится сгенерировать новую информацию, вы можете только повторить существующую. Поэтому данного решения недостаточно, чтобы избавиться от эффекта переобучения. Продолжая борьбу с ним, добавим в модель слой Dropout, непосредственно перед полносвязным классификатором, который будет выполнять прореживание.
И последнее, что следует знать о слоях обогащения изображений случайными преобразованиями: так же как Dropout, они неактивны на этапе прогнозирования (когда вызывается метод predict() или evaluate()). Во время оценки модель будет вести себя так, как если бы мы не задействовали прореживание и обогащение данных.
Пример 8.16. Определение новой сверточной нейронной сети с обогащением и прореживанием
inputs = keras.Input(shape=(180, 180, 3)) x = data_augmentation(inputs) x = layers.Rescaling(1./255)(x) x = layers.Conv2D(filters=32, kernel_size=3, activation="relu")(x) x = layers.MaxPooling2D(pool_size=2)(x) x = layers.Conv2D(filters=64, kernel_size=3, activation="relu")(x) x = layers.MaxPooling2D(pool_size=2)(x) x = layers.Conv2D(filters=128, kernel_size=3, activation="relu")(x) x = layers.MaxPooling2D(pool_size=2)(x) x = layers.Conv2D(filters=256, kernel_size=3, activation="relu")(x) x = layers.MaxPooling2D(pool_size=2)(x) x = layers.Conv2D(filters=256, kernel_size=3, activation="relu")(x) x = layers.Flatten()(x) x = layers.Dropout(0.5)(x) outputs = layers.Dense(1, activation="sigmoid")(x) model = keras.Model(inputs=inputs, outputs=outputs) model.compile(loss="binary_crossentropy", optimizer="rmsprop", metrics=["accuracy"])
Теперь обучим модель, используя обогащение и прореживание данных. Поскольку ожидается, что переобучение произойдет намного позже, зададим в три раза больше эпох обучения - 100.
Пример 8.17. Обучение регуляризованной модели
callbacks = [
keras.callbacks.ModelCheckpoint(
filepath="convnet_from_scratch_with_augmentation.keras",
save_best_only=True,
monitor="val_loss")
]
history = model.fit(
train_dataset,
epochs=100,
validation_data=validation_dataset,
callbacks=callbacks)
И снова выведем графики с результатами (рисунок 2).
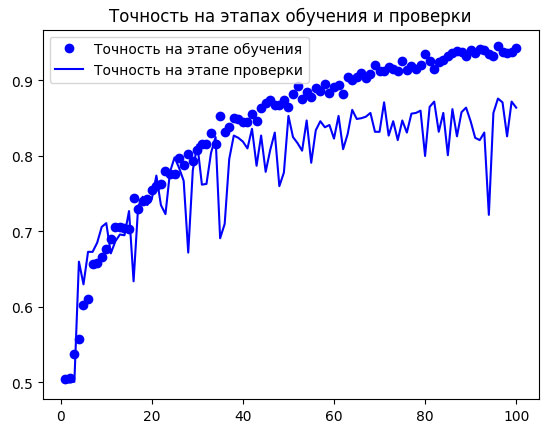
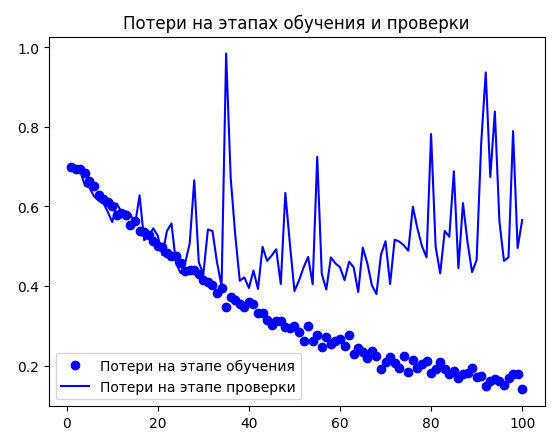
Рис.2. Графики изменения метрик на этапе проверки при обучении модели с обогащением данных
Благодаря обогащению и прореживанию данных переобучение наступило намного позже - в районе 60-70-й эпохи (сравните с десятью эпохами в оригинальной модели). Точность на этапе проверки остановилась в районе 80-85% - существенное улучшение по сравнению с первой попыткой.
Теперь проверим точность на контрольных данных .
Пример 8.18. Оценка модели на контрольном наборе данных
test_model = keras.models.load_model(
"convnet_from_scratch_with_augmentation.keras")
test_loss, test_acc = test_model.evaluate(test_dataset)
print(f"Test accuracy: {test_acc:.3f}")
Блокнот с этим примером можно взять здесь.
Точность на контрольных данных составила 84,7%. Уже неплохо! Если для экспериментов вы используете Colab, то не забудьте загрузить сохраненный файл (convnet_from_scratch_with_augmentation.keras): мы возьмем его для экспериментов в следующих шагах.
Используя дополнительные методы регуляризации и настраивая параметры сети (например, число фильтров на сверточный слой или число слоев в сети), можно добиться еще более высокой точности: примерно 90%. Однако будет очень трудно подняться выше этой отметки, обучая сверточную нейронную сеть с нуля, потому что у нас слишком мало данных. Следующий шаг к увеличению точности решения нашей задачи заключается в использовании предварительно обученной модели, но об этом мы поговорим в следующих шагах.
Со следующего шага мы начнем рассматривать использование предварительно обученной модели.
