На этом шаге мы рассмотрим этот пример.
Чтобы сегментировать изображение, в глубоком обучении используется модель для назначения класса каждому пикселю изображения - таким образом изображение сегментируется на разные зоны (например "фон" и "передний план" или "дорога", "автомобиль" и "тротуар"). Данная категория методов может найти применение в инструментах редактирования изображений и видео, автоматическом управлении транспортными средствами, робототехнике, медицине и т. д.
Есть два разных варианта сегментации изображений (рисунок 1).

Рис.1. Семантическая сегментация и сегментация экземпляров
- Семантическая сегментация - когда каждый пиксель независимо друг от друга относится к некоторой семантической категории (скажем, "кошка").
В этом случае, если на изображении есть две кошки, все соответствующие пиксели будут включены в одну и ту же общую категорию - "кошка" (рисунок 1).
- Сегментация экземпляров - направлена не только на классификацию пикселей изображения по категориям, но и на выделение отдельных экземпляров
объекта. Поэтому на изображении с двумя кошками экземпляры "кошка 1" и "кошка 2" будут распознаны как две отдельные группы пикселей.
Сосредоточимся на семантической сегментации: в примере ниже мы еще раз исследуем изображения кошек и собак, но на этот раз постараемся научиться различать основной предмет и его фон.
Для работы нам понадобится набор данных Oxford-IIIT Pets (https://www.robots.ox.ac.uk/~vgg/data/pets/), содержащий 7390 изображений различных пород кошек и собак вместе с соответствующими масками сегментации.
 При необходимости его можно взять здесь.
При необходимости его можно взять здесь.
Маска сегментации - это эквивалент метки в задаче сегментации изображения; изображение того же размера, что и входное изображение, с одним цветовым каналом, в котором каждое целочисленное значение обозначает класс соответствующего пикселя на входном изображении. В нашем случае пиксели масок сегментации могут принимать одно из трех целочисленных значений:
- 1 (передний план);
- 2 (фон);
- 3(контур).
Для начала загрузим и распакуем набор данных, использовав утилиты wget и tar:
!wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz !wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz !tar -xf images.tar.gz !tar -xf annotations.tar.gz
Входные изображения сохраняются в виде файлов JPG в папке images/ (например, images/Abyssinian_1.jpg), а соответствующие маски сегментации - в виде файлов PNG с теми же именами в папке annotations/trimaps/ (например, annotations/trimaps/Abyssinian_1.png).
Подготовим список путей к входным файлам и файлам масок:
import os input_dir = "images/" target_dir = "annotations/trimaps/" input_img_paths = sorted( [os.path.join(input_dir, fname) for fname in os.listdir(input_dir) if fname.endswith(".jpg")]) target_paths = sorted( [os.path.join(target_dir, fname) for fname in os.listdir(target_dir) if fname.endswith(".png") and not fname.startswith(".")])
А теперь посмотрим, как выглядит одно из входных изображений и его маска. Выведем на экран изображение (рисунок 2):
import matplotlib.pyplot as plt from tensorflow.keras.utils import load_img, img_to_array plt.axis("off") # Вывести девятое входное изображение plt.imshow(load_img(input_img_paths[9]))

Рис.2. Пример изображения

Рис.3. Соответствующая целевая маска
В исходном наборе данных метки имеют значения 1, 2 и 3. Мы вычитаем 1, чтобы привести метки в диапазон от 0 до 2, а затем умножаем на 127, чтобы получить метки 0 (черный цвет), 127 (серый), 254 (почти белый).
def display_target(target_array): # В исходном наборе данных метки имеют значения 1, 2 и 3. # Мы вычитаем 1, чтобы привести метки в диапазон от 0 до 2, # а затем умножаем на 127, чтобы получить метки 0 (черный цвет), # 127 (серый), 254 (почти белый) normalized_array = (target_array.astype("uint8") - 1) * 127 plt.axis("off") plt.imshow(normalized_array[:, :, 0]) # Аргумент color_mode="grayscale" обеспечивает обработку загружаемого # изображения как имеющего единственный цветовой канал img = img_to_array(load_img(target_paths[9], color_mode="grayscale")) display_target(img)
Аргумент color_mode="grayscale" обеспечивает обработку загружаемого изображения как имеющего единственный цветовой канал.
Далее загрузим входные данные и цели в два массива NumPy и разделим массивы на обучающий и проверочный. Так как набор данных невелик, его можно целиком загрузить в память:
import numpy as np import random # Все изображения будут масштабироваться до размеров 200 × 200 img_size = (200, 200) # Общее количество образцов num_imgs = len(input_img_paths) # Перемешивание файлов (изначально они были отсортированы по породам). # В обеих инструкциях используется одно и то же начальное число (1337), # чтобы гарантировать единый порядок входных и целевых файлов random.Random(1337).shuffle(input_img_paths) random.Random(1337).shuffle(target_paths) def path_to_input_image(path): return img_to_array(load_img(path, target_size=img_size)) def path_to_target(path): img = img_to_array( load_img(path, target_size=img_size, color_mode="grayscale")) # Вычитается 1, чтобы преобразовать метки в 0, 1 и 2 img = img.astype("uint8") - 1 return img # агрузка всех изображений в массив input_imgs типа float32 и масок в # массив targets типа uint8 (в одном и том же порядке). Входные изображения # имеют три канала (значения RBG), а цели - один канал # (с целочисленными метками) input_imgs = np.zeros((num_imgs,) + img_size + (3,), dtype="float32") targets = np.zeros((num_imgs,) + img_size + (1,), dtype="uint8") for i in range(num_imgs): input_imgs[i] = path_to_input_image(input_img_paths[i]) targets[i] = path_to_target(target_paths[i]) # Резервирование 1000 образцов для проверочного набора num_val_samples = 1000 # Разделение данных на обучающий и проверочный наборы train_input_imgs = input_imgs[:-num_val_samples] train_targets = targets[:-num_val_samples] val_input_imgs = input_imgs[-num_val_samples:] val_targets = targets[-num_val_samples:]
Теперь определим модель:
from tensorflow import keras from tensorflow.keras import layers def get_model(img_size, num_classes): inputs = keras.Input(shape=img_size + (3,)) x = layers.Rescaling(1./255)(inputs) x = layers.Conv2D(64, 3, strides=2, activation="relu", padding="same")(x) x = layers.Conv2D(64, 3, activation="relu", padding="same")(x) x = layers.Conv2D(128, 3, strides=2, activation="relu", padding="same")(x) x = layers.Conv2D(128, 3, activation="relu", padding="same")(x) x = layers.Conv2D(256, 3, strides=2, padding="same", activation="relu")(x) x = layers.Conv2D(256, 3, activation="relu", padding="same")(x) x = layers.Conv2DTranspose(256, 3, activation="relu", padding="same")(x) x = layers.Conv2DTranspose( 256, 3, activation="relu", padding="same", strides=2)(x) x = layers.Conv2DTranspose(128, 3, activation="relu", padding="same")(x) x = layers.Conv2DTranspose( 128, 3, activation="relu", padding="same", strides=2)(x) x = layers.Conv2DTranspose(64, 3, activation="relu", padding="same")(x) x = layers.Conv2DTranspose( 64, 3, activation="relu", padding="same", strides=2)(x) outputs = layers.Conv2D(num_classes, 3, activation="softmax", padding="same")(x) model = keras.Model(inputs, outputs) return model model = get_model(img_size=img_size, num_classes=3) model.summary()
Вот вывод метода model.summary():
Model: "functional" Layer (type) Output Shape Param # input_layer (InputLayer) (None, 200, 200, 3) 0 rescaling (Rescaling) (None, 200, 200, 3) 0 conv2d (Conv2D) (None, 100, 100, 64) 1,792 conv2d_1 (Conv2D) (None, 100, 100, 64) 36,928 conv2d_2 (Conv2D) (None, 50, 50, 128) 73,856 conv2d_3 (Conv2D) (None, 50, 50, 128) 147,584 conv2d_4 (Conv2D) (None, 25, 25, 256) 295,168 conv2d_5 (Conv2D) (None, 25, 25, 256) 590,080 conv2d_transpose (None, 25, 25, 256) 590,080 (Conv2DTranspose) conv2d_transpose_1 (None, 50, 50, 256) 590,080 (Conv2DTranspose) conv2d_transpose_2 (None, 50, 50, 128) 295,040 (Conv2DTranspose) conv2d_transpose_3 (None, 100, 100, 128) 147,584 (Conv2DTranspose) conv2d_transpose_4 (None, 100, 100, 64) 73,792 (Conv2DTranspose) conv2d_transpose_5 (None, 200, 200, 64) 36,928 (Conv2DTranspose) conv2d_6 (Conv2D) (None, 200, 200, 3) 1,731 Total params: 2,880,643 (10.99 MB) Trainable params: 2,880,643 (10.99 MB) Non-trainable params: 0 (0.00 B)
Первая половина модели очень похожа на типичную сверточную сеть, используемую для классификации изображений: стек слоев Conv2D с постепенно увеличивающимися размерами фильтров. Мы трижды повторяем уменьшение наполовину разрешения наших изображений, что дает активацию с размерами (25, 25, 256). Цель этой первой половины - закодировать изображения в карты признаков меньшего размера, где каждое пространственное местоположение (или пиксель) содержит информацию о большем пространственном фрагменте исходного изображения. Конечный эффект можно интерпретировать как сжатие.
Одно из важных различий между первой половиной этой модели и моделями классификации, которые были показаны ранее, заключается в способе уменьшения разрешения. В сверточных сетях в предыдущих шагах для уменьшения разрешения карт признаков мы использовали слои MaxPooling2D. Здесь мы увеличили шаг свертки во всех остальных сверточных слоях. В случае сегментации изображения важно позаботиться о пространственной привязке информации на изображении, так как на выходе модели должны создаваться попиксельные целевые маски. Поэтому мы выбрали данное решение. Применение метода на основе выбора максимального значения из соседних в окне 2 × 2 полностью уничтожит информацию о местоположении в каждом таком окне: вы получите одно скалярное значение для каждого окна, не имея представления, из которого из четырех местоположений в окне оно было получено. То есть, несмотря на то что данный метод хорошо подходит для задач классификации, в задаче сегментации он нам только навредит. Между тем свертки с увеличенным шагом лучше справляются с уменьшением разрешения карт признаков, когда требуется сохранить информацию о местоположении. Как вы не раз увидите далее, мы будем использовать именно прием увеличения шага свертки вместо выбора максимального значения из соседних в любых моделях, где важно сохранить информацию о местоположении признаков - например, в генеративных моделях.
Вторая половина модели организована как стек слоев Conv2DTranspose. Что это за слои? Дело в том, что результатом первой половины модели является карта признаков с формой (25, 25, 256), а нам нужно получить на выходе результат той же формы, что и целевые маски (200, 200, 3). То есть к выходным данным первой половины модели нужно применить преобразования, увеличивающие разрешение карт признаков. Именно такое преобразование реализует слой Conv2DTranspose: его можно рассматривать как сверточный слой, который учится увеличивать разрешение. Если исходные данные с формой (100, 100, 64) пропустить через слой Conv2D(128, 3, strides=2, padding="same"), то на выходе получится результат формы (50, 50, 128). Если этот вывод пропустить через слой Conv2DTranspose(64, 3, strides=2, padding="same"), получим результат с формой (100, 100, 64), как и у оригинала. То есть после сжатия входных данных в карты признаков с формой (25, 25, 256) с помощью стека слоев Conv2D можно просто применить соответствующую последовательность слоев Conv2DT ranspose, чтобы получить изображения с формой (200, 200, 3).
Теперь скомпилируем и обучим модель:
model.compile(optimizer="rmsprop", loss="sparse_categorical_crossentropy") callbacks = [ keras.callbacks.ModelCheckpoint("oxford_segmentation.keras", save_best_only=True) ] history = model.fit(train_input_imgs, train_targets, epochs=50, callbacks=callbacks, batch_size=64, validation_data=(val_input_imgs, val_targets))
и построим графики изменения потерь на этапах обучения и проверки (рисунок 4):
epochs = range(1, len(history.history["loss"]) + 1) loss = history.history["loss"] val_loss = history.history["val_loss"] plt.figure() plt.plot(epochs, loss, "bo", label="Потери на этапе обучения") plt.plot(epochs, val_loss, "b", label="Потери на этапе проверки") plt.title("Потери на этапах обучения и проверки") plt.legend()
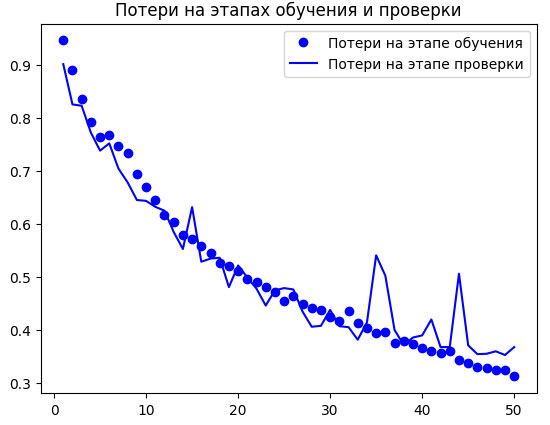
Рис.4. Графики изменения потерь на этапах обучения и проверки
Как видите, на полпути (где-то в районе 25-й эпохи) начал проявляться эффект переобучения. Загрузим модель, показавшую наименьшие потери на проверочных данных, и посмотрим, как ее использовать для прогнозирования маски сегментации (рисунок 5):
from tensorflow.keras.utils import array_to_img model = keras.models.load_model("oxford_segmentation.keras") test_image = val_input_imgs[i] # Исходное изображение plt.axis("off") plt.imshow(array_to_img(test_image)) mask = model.predict(np.expand_dims(test_image, 0))[0] # Утилита для вывода прогноза модели def display_mask(pred): mask = np.argmax(pred, axis=-1) mask *= 127 plt.axis("off") plt.imshow(mask) display_mask(mask)
Блокнот с этим примером можно взять здесь.


Рис.5. Контрольное изображение и спрогнозированная для него маска
В получившейся маске есть пара небольших артефактов, обусловленных присутствием геометрических фигур на переднем и заднем планах, но в целом модель дала довольно точный результат.
До сих пор вы знакомились с основами классификации и сегментации изображений. С имеющимися теперь у вас знаниями можно многого добиться. Тем не менее сверточные нейронные сети, которые опытные инженеры разрабатывают для решения реальных задач, не так просты, как в наших примерах. Вы пока не сможете, подобно экспертам, в процессе конструирования моделей быстро принимать точные решения. Чтобы восполнить этот пробел, вам нужно познакомиться с архитектурными шаблонами. Давайте займемся этим прямо сейчас.
На следующем шаге мы рассмотрим современные архитектурные шаблоны сверточных сетей.
