На этом шаге мы рассмотрим особенности использования такой свертки.
Что бы вы подумали, если бы узнали, что существует такой слой, который можно использовать взамен Conv2D и таким образом сделать модель более легкой (с меньшим количеством обучаемых весовых параметров) и быстрой (с меньшим количеством операций с вещественными числами), а также повысить качество решения задачи на несколько процентных пунктов? Всеми перечисленными свойствами обладает слой раздельной свертки по глубине (SeparableConv2D в Keras). Этот слой выполняет пространственную свертку каждого канала во входных данных в отдельности перед смешиванием выходных каналов посредством поточечной свертки (свертки 1 × 1), как показано на рисунке 1.
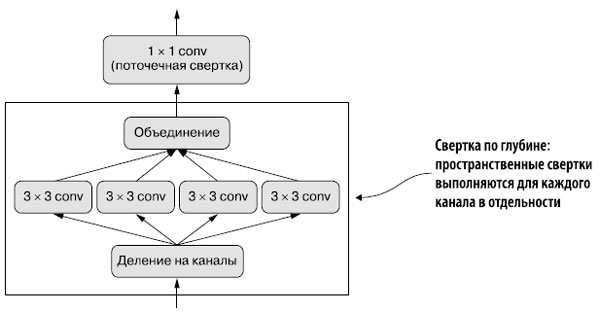
Рис.1. Раздельная свертка по глубине: за сверткой по глубине следует поточечная свертка
Это эквивалентно раздельному выделению пространственных и канальных признаков. Подобно тому как свертка основана на предположении об отсутствии связи закономерностей в изображениях с определенными местоположениями, раздельная свертка по глубине основывается на предположении сильной корреляции пространственных местоположений в промежуточных активациях и практически полной независимости разных каналов. Поскольку это предположение обычно верно для изучаемых глубокими нейронными сетями изображений, оно служит полезным предварительным условием, которое помогает модели эффективнее использовать обучающие данные. Модель с более строгими предварительными предположениями о структуре информации, которую она должна обрабатывать, является лучшей, если предварительные предположения точны.
Раздельная свертка по глубине требует намного меньше параметров и выполняет меньше вычислений по сравнению с обычной сверткой, обладая при этом сопоставимой репрезентативной мощностью. В результате получаются модели меньшего размера, которые сходятся быстрее и менее подвержены переобучению. Эти преимущества особенно важны при обучении небольших моделей с нуля на ограниченном наборе данных.
В отношении крупных моделей раздельные свертки по глубине составляют основу архитектуры Xception высококачественных сверточных нейронных сетей, входящей в состав Keras. Узнать больше о теоретических основах раздельной свертки по глубине и архитектуре Xception можно в статье "Xception: Deep Learning with Depthwise Separable Convolutions".
 Chollet F. Xception: Deep Learning with Depthwise Separable Convolutions // Conference on Computer Vision and Pattern Recognition, 2017,
https://arxiv.org/abs/1610.02357.
Chollet F. Xception: Deep Learning with Depthwise Separable Convolutions // Conference on Computer Vision and Pattern Recognition, 2017,
https://arxiv.org/abs/1610.02357.
Одновременная эволюция оборудования, программного обеспечения и алгоритмов
Рассмотрим обычную операцию свертки с окном 3 × 3, 64 входными каналами и 64 выходными каналами. В ней используется 3 × 3 × 64 × 64 = 36 864 обучаемых параметра. При применении ее к изображению будет выполнено множество действий с вещественными числами, пропорционально количеству параметров. А теперь представьте эквивалентную раздельную свертку по глубине: она включает всего 3 × 3 × 64 + 64 × 64 = 4672 обучаемых параметра и выполняет намного меньше действий с вещественными числами. Разница в эффективности увеличивается еще больше с увеличением количества фильтров или размеров окон свертки.
То есть при использовании раздельной свертки по глубине можно ожидать значительного ускорения? Не торопитесь с выводами. Утверждение было бы верным, если бы вы писали простые реализации алгоритмов на CUDA или C. На самом деле значительное ускорение можно увидеть на CPU при использовании распараллеленной базовой реализации на C. Но на практике вы, вероятно, берете GPU - и ваши фактические реализации весьма далеки от "простых" реализаций CUDA: это ядро cuDNN, фрагмент кода, чрезвычайно оптимизированный, вплоть до каждой машинной инструкции. Безусловно, на оптимизацию подобного кода нужно потратить много усилий, ведь свертки cuDNN на оборудовании NVIDIA выполняют много квинтиллионов операций с плавающей точкой каждый день. Однако подобная экстремальная оптимизация имеет один побочный эффект: альтернативные подходы почти не дают преимуществ в производительности, даже те с существенными внутренними преимуществами (как раздельные свертки по глубине).
Несмотря на неоднократные обращения к NVIDIA, раздельные свертки по глубине так и не получили того же уровня программной и аппаратной оптимизации, что и обычные. В результате скорости их выполнения остаются примерно одинаковыми, несмотря на то что параметров и операций с плавающей точкой у них квадратично меньше. И все же использование раздельных по глубине сверток остается хорошей идеей даже в отсутствие ускорения: меньшее количество параметров означает меньшую подверженность риску переобучения, а предположение о независимости каналов приводит к более быстрой сходимости модели и получению более надежных представлений.
Небольшое неудобство в одном случае может превратиться в непроходимую стену в другом: вся аппаратная и программная экосистема глубокого обучения оптимизирована для очень конкретного набора алгоритмов (в частности, сверточных сетей, обучаемых через обратное распространение) и любое отклонение от проторенных дорог обходится чрезвычайно дорого. Если вам доведется экспериментировать с альтернативными алгоритмами, такими как безградиентная оптимизация или спайковые нейронные сети (Spiking Neural Networks), то первые ваши параллельные реализации на C++ или CUDA будут на порядки медленнее старой доброй сверточной сети, и неважно, насколько умны и эффективны ваши идеи. Вам будет сложно убедить других исследователей принять ваш метод, даже если он окажется лучше. Современное глубокое обучение является продуктом коэволюции оборудования, программного обеспечения и алгоритмов. Доступность графических процессоров NVIDIA и CUDA привела к первому успеху сверточных сетей, обучаемых через обратное распространение, что заставило NVIDIA оптимизировать свои аппаратные и программные технологии для этих алгоритмов. Это, в свою очередь, привело к консолидации исследовательского сообщества вокруг данных методов. Выбор же другого пути в настоящее время потребует многолетней реорганизации всей экосистемы.
На следующем шаге мы соберем мини-модель с архитектурой Xception.
