На этом шаге мы продолжим тестирование созданной нейронной сети.
Продолжим в том же духе и напишем код, позволяющий проверить, насколько хорошо нейронная сеть справляется с остальной частью набора данных, и провести подсчет правильных результатов, чтобы впоследствии мы могли оценивать плодотворность своих будущих идей по совершенствованию способности сети обучаться, а также сравнивать наши результаты с результатами, полученными другими людьми.
Сначала ознакомьтесь с приведенным ниже кодом, а затем мы его обсудим.
# журнал оценок работы сети, первоначально пустой scorecard = [] # перебрать все записи в тестовом наборе данных for record in test_data_list: # получить список значений из записи, используя символы # запятой (',') в качестве разделителей all_values = record.split(',') # правильный ответ - первое значение correct_label = int (all_values[0]) print(correct_label, "истинный маркер") # масштабировать и сместить входные значения inputs = (numpy.asfarray(all_values[1:]) / 255 * 0.99) + 0.01 # опрос сети outputs = n.query(inputs) # индекс наибольшего значения является маркерным значением label = numpy.argmax(outputs) print(label, "ответ сети") # присоединить оценку ответа сети к концу списка if (label == correct_label): # в случае правильного ответа сети присоединить # к списку значение 1 scorecard.append(1) else: # в случае неправильного ответа сети присоединить # к списку значение 0 scorecard.append(0)
Прежде чем войти в цикл, обрабатывающий все записи тестового набора данных, мы создаем пустой список scorecard, который будет служить нам журналом оценок работы сети, обновляемым после обработки каждой записи.
В цикле мы делаем то, что уже делали раньше: извлекаем значения из текстовой записи, в которой они разделены запятыми. Первое значение, указывающее правильный ответ, сохраняется в отдельной переменной. Остальные значения масштабируются, чтобы их можно было использовать в качестве входных данных для передачи запроса нейронной сети. Ответ нейронной сети сохраняется в переменной outputs.
Далее следует довольно интересная часть кода. Мы знаем, что наибольшее из значений выходных узлов рассматривается сетью в качестве правильного ответа. Индекс этого узла, т.е. его позиция, соответствует маркеру. Эта фраза просто означает, что первый элемент соответствует маркеру "0", пятый - маркеру "4" и т.д. К счастью, существует удобная функция библиотеки numpy, которая находит среди элементов массива максимальное значение и сообщает его индекс. Это функция numpy.argmax(). Для получения более подробных сведений о ней можете посетить веб-страницу по следующему адресу: https://docs.scipy.org/doc/numpy-1.10.1/reference/generated/numpy.argmax.html.
Возврат этой функцией значения 0 означает, что правильным ответом сеть считает "0" и т.д.
В последнем фрагменте кода полученный маркер сравнивается с известным корректным маркером. Если оба маркера одинаковы, в журнал записывается "1", в противном случае - "0".
Кроме того, мы включили в некоторых местах кода полезную команду print(), чтобы мы сами могли отслеживать правильные и предсказываемые значения. Ниже представлены результаты выполнения этого кода вместе с выведенными записями нашего рабочего журнала.
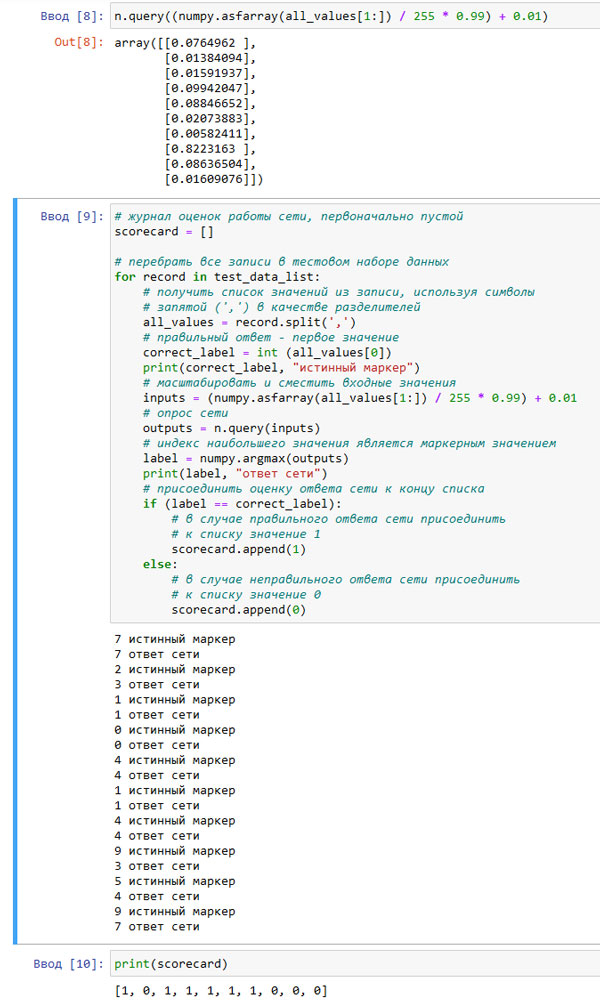
Рис.1. Результат работы приложения
На этот раз не все у нас хорошо! Вы видите, что имеется несколько несовпадений. Последняя выведенная строка результатов показывает, что из десяти тестовых записей правильно были распознаны 6. Таким образом, доля правильных результатов составила 60%. На самом деле это не так уж и плохо, если принять во внимание небольшой размер тренировочного набора, который мы использовали.
Дополним код фрагментом, который будет выводить относительную долю правильных ответов в виде дроби.
# рассчитать показатель эффективности в виде # доли правильных ответов scorecard_array = numpy.asarray(scorecard) print("эффективность = ", scorecard_array.sum() / scorecard_array.size)
Эта доля рассчитывается как количество всех записей в журнале, содержащих "1", деленное на общее количество записей (размер журнала). Вот каким получается результат.
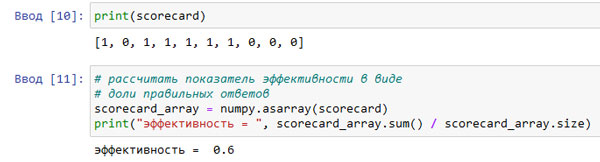
Рис.2. Результаты расчета эффективности
Как и ожидалось, мы получили показатель эффективности сети, равный 0,6, или 60%.
На следующем шаге мы рассмотрим тренировку и тестированое нейронной сети на полной базе данных.
