На этом шаге мы рассмотрим реализацию такой классификации.
Посмотрим теперь на замечательную методику машинного обучения: обучение ансамблей (ensemble learning). Если степень безошибочности
предсказаний вашей модели недостаточно высока, а срок сдачи проекта уже на носу - совет: попробуйте этот подход метаобучения, сочетающий предсказания
(классификации) нескольких алгоритмов машинного обучения. Во многих случаях с его помощью вы сможете добиться в последнюю минуту лучших результатов.
Общее описание
В предыдущих шагах мы изучили несколько алгоритмов машинного обучения, с помощью которых можно быстро получить неплохие результаты.
Однако у разных алгоритмов - разные сильные стороны. Например, основанные на нейронных сетях классификаторы способны давать великолепные результаты для сложных задач, однако подвержены риску переобучения именно вследствие своих потрясающих способностей к усвоению тонких закономерностей данных. Обучение ансамблей для задач классификации частично решает проблему, связанную с тем, что заранее неизвестно, какой алгоритм машинного обучения сработает лучше всего.
Как работает этот подход? Создается метаклассификатор, состоящий из нескольких типов или экземпляров простых алгоритмов машинного обучения. Другими словами, обучается несколько моделей. В целях классификации конкретного наблюдения входные данные передаются по отдельности всем моделям. А роль метапредсказания играет класс, который эти модели возвращали чаще всего при этих входных данных. Он и становится итоговым результатом алгоритма обучения ансамблей.
Случайные леса (random forests) - особая разновидность алгоритмов обучения ансамблей, использующая обучение на основе деревьев принятия решений. Лес состоит из множества деревьев. Аналогично, случайный лес состоит из множества деревьев принятия решений. Отдельные деревья принятия решений получаются путем внесения стохастичности в процесс генерации деревьев на этапе обучения (например, выбор в качестве первой различных вершин дерева). В результате получаются различные деревья принятия решений - как раз то, что нужно. На рисунке 1 показан процесс предсказания для обученного случайного леса при следующем сценарии. У Алисы выраженные способности к математике и языкам. Ансамбль состоит из трех деревьев принятия решений (составляющих случайный лес). Чтобы классифицировать Алису, мы просим все эти деревья ее классифицировать. Два из трех деревьев классифицируют Алису как специалиста по computer science. Этот класс как получивший максимум "голосов" и возвращается в качестве окончательного результата классификации.
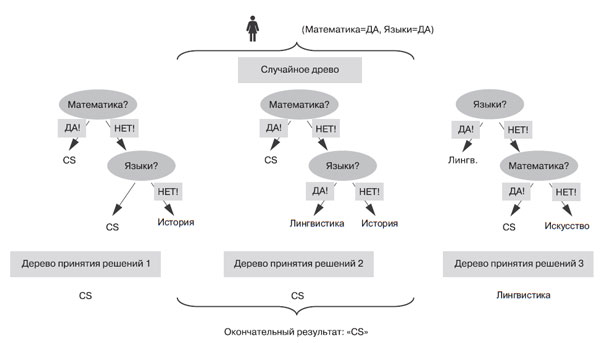
Рис.1. Классификатор на основе случайного леса агрегирует результаты трех деревьев принятия решений
Код
Продолжим работать с этим примером классификации изучаемых предметов на основе демонстрируемых студентами способностей в трех областях: математика, языки и творчество. Возможно, вам кажется, что реализовать метод обучения ансамблей на Python непросто. Но благодаря многогранности библиотеки scikit-learn это не так (пример 4.10).
Пример 4.10. Обучение ансамблей с помощью классификаторов на основе случайных лесов
## Зависимости import numpy as np from sklearn.ensemble import RandomForestClassifier ## Данные: оценки студентов по (математика, языки, творческие ## способности) --> предмет для изучения X = np.array([[9, 5, 6, "computer science"], [5, 1, 5, "computer science"], [8, 8, 8, "computer science"], [1, 10, 7, "literature"], [1, 8, 1, "literature"], [5, 7, 9, "art"], [1, 1, 6, "art"]]) ## Однострочник Forest = RandomForestClassifier(n_estimators=10).fit(X[:, :-1], X[:, -1]) ## Результат students = Forest.predict([[8, 6, 5], [3, 7, 9], [2, 2, 1]]) print(students)
Попробуйте догадаться, каковы будут результаты выполнения этого фрагмента кода.
Принцип работы
Инициализировав массив маркированных обучающих данных в примере4.10, код создает случайный лес с помощью конструктора класса RandomForestClassifier с одним параметром - n_estimators, - задающим количество деревьев в лесу. Далее мы вызываем функцию fit(), заполняя данными полученную при инициализации модель (пустой лес). Используемые для этого входные обучающие данные состоят из всех столбцов массива X, кроме последнего, а метки обучающих данных задаются в этом последнем столбце. Как и в предыдущих примерах, соответствующие столбцы из массива данных X мы выделяем с помощью срезов.
Относящаяся к классификации часть этого фрагмента кода несколько отличается. Мы хотели показать вам, как классифицировать много наблюдений, а не только одно. Это можно сделать тут путем создания многомерного массива, в котором каждому наблюдению соответствует одна строка.
Вот результаты работы нашего фрагмента кода:
## Результат students = Forest.predict([[8, 6, 5], [3, 7, 9], [2, 2, 1]]) print(students) # ['computer science' 'literature' 'art']
Обратите внимание, что результаты по-прежнему недетерминистичны (могут отличаться при различных запусках этого кода), поскольку в алгоритме случайных лесов используется генератор случайных чисел, возвращающий различные числа в различные моменты времени. Детерминизировать этот вызов можно с помощью целочисленного аргумента random_state. Например, можно задать параметр random_state=1 при вызове конструктора случайного леса:
RandomForestClassifier(n_estimators=10, random_state=1) .
В этом случае при каждом создании классификатора на основе случайных лесов будут возвращаться одни и те же результаты, поскольку будут генерироваться одни и те же случайные числа: в основе их всех лежит начальное значение генератора 1.
Резюмируя: в этом шаге представлен метаподход к классификации: снижение дисперсии погрешности классификации за счет использования результатов работы нескольких различных деревьев решений - одна из версий обучения ансамблей, при котором несколько базовых моделей объединяется в одну метамодель, способную задействовать все сильные стороны каждой из них.
 Использование двух различных деревьев принятия решений может привести к высокой дисперсии погрешности, если одно возвращает хорошие результаты, а второе - нет.
Последствия этого эффекта можно уменьшить с помощью случайных лесов.
Использование двух различных деревьев принятия решений может привести к высокой дисперсии погрешности, если одно возвращает хорошие результаты, а второе - нет.
Последствия этого эффекта можно уменьшить с помощью случайных лесов.
Различные вариации этой идеи очень распространены в машинном обучении. Чтобы быстро повысить степень безошибочности модели, просто запустите несколько моделей машинного обучения и найдите среди их результатов лучшие (маленький секрет специалистов по машинному обучению). Методики обучения ансамблей в некотором смысле автоматически выполняют задачи, часто возлагаемые на экспертов по конвейерам машинного обучения: выбор, сравнение и объединение результатов различных моделей машинного обучения. Основное преимущество обучения ансамблей - возможность выполнения его по отдельности для каждого значения данных во время выполнения.
На следующем шаге мы подведем некоторые итоги.
