На этом шаге мы рассмотрим связь между энтропией и информацией.
Поучительность только что
рассмотренного примера в том, что из
него отчетливо видно как предшествующий опыт
(![]() ) может
уменьшить количество исходов и, следовательно, неопределенность последующего
опыта (
) может
уменьшить количество исходов и, следовательно, неопределенность последующего
опыта (![]() ).
Разность H(
).
Разность H(![]() ) и
) и
![]() ,
очевидно, показывает, какие новые сведения относительно
,
очевидно, показывает, какие новые сведения относительно
![]() мы
получаем, произведя опыт
мы
получаем, произведя опыт ![]() . Эта
величина называется информацией относительно опыта
. Эта
величина называется информацией относительно опыта
![]() ,
содержащейся в опыте
,
содержащейся в опыте ![]() .
.
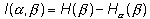 (1.13)
(1.13)
Данное выражение открывает возможность численного измерения количества информации, поскольку оценивать энтропию мы уже умеем. Из него легко получить ряд следствий.
Следствие 1. Поскольку единицей измерения энтропии является бит, то в этих же единицах может быть измерено количество информации.
Следствие 2.
Пусть опыт ![]() =
=
![]() , т.е.
просто произведен опыт
, т.е.
просто произведен опыт ![]() .
Поскольку он несет полную информацию о себе самом, неопределенность его исхода
полностью снимается, т.е.
.
Поскольку он несет полную информацию о себе самом, неопределенность его исхода
полностью снимается, т.е. ![]()
![]() =0. Тогда
I(
=0. Тогда
I(![]() ,
,
![]() ) = H
(
) = H
(![]() ), т.е.
можно считать, что энтропия равна информации относительно опыта, которая
содержится в нем самом.
), т.е.
можно считать, что энтропия равна информации относительно опыта, которая
содержится в нем самом.
Можно построить уточнение: энтропия опыта равна той информации, которую мы получаем в результате его осуществления.
Отметим ряд свойств информации.
- I(
 ,
,
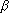 )
)
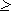 0, причем
I(,
) = 0
тогда и только тогда, когда опыты
и
независимы.
Это свойство непосредственно вытекает из (1.10)
и (1.13).
0, причем
I(,
) = 0
тогда и только тогда, когда опыты
и
независимы.
Это свойство непосредственно вытекает из (1.10)
и (1.13).
- I(,
) = I(
,
), т.е.
информация симметрична относительно последовательности опытов.
- Следствие 2 и представление энтропии в виде (1.4) позволяют записать:
 (1.14)
(1.14)
т.е. информация опыта равна среднему значению количества информации, содержащейся в каком-либо одном его исходе.
Рассмотрим ряд примеров применения формулы (1.14).
Пример 1. Какое количество информации требуется, чтобы узнать исход броска монеты? В данном случае n=2 и события равновероятны, т.е. p1=p2=0,5. Согласно (1.14):
I = – 0,5•log20,5 – 0,5•log20,5 = 1 бит
Пример 2. Игра "Угадай-ка – 4". Некто задумал целое число в интервале от 0 до 3. Наш опыт состоит в угадывании этого числа. На наши вопросы Некто может отвечать лишь "Да" или "Нет". Какое количество информации мы должны получить, чтобы узнать задуманное число, т.е. полностью снять начальную неопределенность? Как правильно построить процесс угадывания?
Исходами в данном случае являются: A1 – "задуман 0", A2 – "задумана 1", A3 – "задумана 2", A4 – "задумана 3". Конечно, предполагается, что вероятности быть задуманными у всех чисел одинаковы. Поскольку n = 4, следовательно, p(Ai)=1/4, log2 p(Ai)= –2 и I = 2 бит. Таким образом, для полного снятия неопределенности опыта (угадывания задуманного числа) нам необходимо 2 бита информации.
Теперь выясним, какие вопросы необходимо задать, чтобы процесс угадывания был оптимальным, т.е. содержал минимальное их число. Здесь удобно воспользоваться так называемым выборочным каскадом:
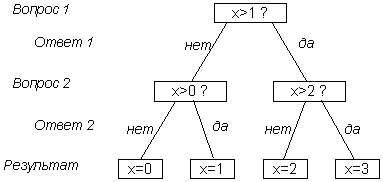
Таким образом, для решения задачи оказалось достаточно 2-х вопросов независимо от того, какое число было задумано. Совпадение между количеством информации и числом вопросов с бинарными ответами неслучайно.
Количество информации численно равно числу вопросов с равновероятными бинарными вариантами ответов, которые необходимо задать, чтобы полностью снять неопределенность задачи.
В рассмотренном примере два полученных ответа в выборочном каскаде полностью сняли начальную неопределенность. Подобная процедура позволяет определить количество информации в любой задаче, интерпретация которой может быть сведена к парному выбору. Например, определение символа некоторого алфавита, использованного для представления сообщения. Приведенное утверждение перестает быть справедливым в том случае, если каждый из двух возможных ответов имеет разную вероятность – такая ситуация будет рассмотрена позднее.
Легко получить следствие формулы (1.14) для случая, когда все n исходов равновероятны (собственно, именно такие и рассматривались в примерах 1 и 2. В этом случае все

I = log2n (1.15)
Эта формула была выведена в 1928 г. американским инженером Р.Хартли и носит его имя. Она связывает количество равновероятных состояний (n) и количество информации в сообщении (I), что любое из этих состояний реализовалось. Ее смысл в том, что, если некоторое множество содержит n элементов и x принадлежит данному множеству, то для его выделения (однозначной идентификации) среди прочих требуется количество информации, равное log2n.
Частным случаем применения формулы (1.15) является ситуация, когда n=2k; подставляя это значение в (1.15), очевидно, получим:
I = k бит (1.16)
Именно эта ситуация реализовалась в примерах 1 и 2. Анализируя результаты решения, можно прийти к выводу, что k как раз равно количеству вопросов с бинарными равновероятными ответами, которые определяли количество информации в задачах.
Пример 3. Случайным образом вынимается карта из колоды в 32 карты. Какое количество информации требуется, чтобы угадать, что это за карта? Как построить угадывание?
Для данной ситуации n = 25, значит, k = 5 и, следовательно, I = 5 бит. Последовательность вопросов придумайте самостоятельно.
Пример 4. В некоторой местности имеются две близкорасположенные деревни: A и B. Известно, что жители A всегда говорят правду, а жители B – всегда лгут. Известно также, что жители обеих деревень любят ходить друг к другу в гости, поэтому в каждой из деревень можно встретить жителя соседней деревни. Путешественник, сбившись ночью с пути оказался в одной из двух деревень и, заговорив с первым встречным, захотел выяснить, в какой деревне он находится и откуда его собеседник. Какое минимальное количество вопросов с бинарными ответами требуется задать путешественнику?
Количество возможных комбинаций, очевидно, равно 4 (путешественник в A, собеседник из A; путешественник в A, собеседник из B; и т.д.), т.е. n = 22 и, следовательно значит, k = 2. Последовательность вопросов придумайте самостоятельно.
Попытаемся понять смысл полученных в данном разделе результатов. Необходимо выделить ряд моментов.
1. (1.14) является
статистическим определением понятия "информация", поскольку в него входят
вероятности возможных исходов опыта. По сути, мы даем операционное определение
новой величины, т.е. устанавливаем процедуру (способ) измерения величины. Как
отмечалось ранее, в науке (научном знании) именно такой метод введения новых
терминов считается предпочтительным, поскольку то, что не может быть измерено,
не может быть проверено и, следовательно, заслуживает меньшего доверия.
Выражение (1.13)
интерпретировать следующим образом: если начальная энтропия опыта H1,
а в результате сообщения информации I энтропия становится равной H2
(очевидно, H1![]() H2),
то
H2),
то
I = H1 – H2,
т.е. информация равна убыли энтропии. В
частном случае, если изначально равновероятных исходов было n1, а в
результате передачи информации I неопределенность уменьшилась, и число исходов
стало n2 (очевидно, n2
![]() n1),
то из (1.15) легко получить:
n1),
то из (1.15) легко получить:
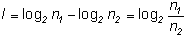
Таким образом, можно дать следующее определение: Информация – это содержание сообщения, понижающего неопределенность некоторого опыта с неоднозначным исходом; убыль связанной с ним энтропии является количественной мерой информации. В случае равновероятных исходов информация равна логарифму отношения числа возможных исходов до и после (получения сообщения).
2. Как уже было сказано, в статистической механике энтропия характеризует неопределенность, связанную с недостатком информации о состоянии системы. Наибольшей оказывается энтропия у равновесной полностью беспорядочной системы – о ее состоянии наша осведомленность минимальна. Упорядочение системы (наведение какого-то порядка) связано с получением некоторой дополнительной информации и уменьшением энтропии. В теории информации энтропия также отражает неопределенность, однако, это неопределенность иного рода – она связана с незнанием результата опыта с набором случайных возможных исходов. Таким образом, хотя между энтропией в физике и информатике много общего, необходимо сознавать и различие этих понятий. Совершенно очевидно, что мы в дальнейшем понятие энтропии будем использовать в аспекте теории информации.
Следствием аддитивности энтропии независимых опытов оказывается аддитивность информации. Пусть с выбором одного из элементов (xA) множества A, содержащего nA элементов, связано IA = log2 nA информации, а с выбором xB из B с nB элементами информации связано IB = log2 nB и второй выбор никак не связан с первым, то при объединении множеств число возможных состояний (элементов) будет n = nA·nB и для выбора комбинации xAxB потребуется количество информации:
I = log2n = log2 nA· log2 nB = log2 nA + log2 nB = IA + IB
Вернемся к
утверждению о том, что количество информации может быть измерено числом вопросов
с двумя равновероятными ответами. Означает ли это, что I должна быть всегда
величиной целой? Из формулы Хартли (1.15), как было показано, I = k бит (т.е. целому числу бит) только в случае
n = 2k. А в остальных ситуациях? Например, при игре "Угадай-ка – 7"
(угадать число от 0 до 6) нужно в выборочном каскаде задать m
![]() log2
7 = 2,807 < log2 8 = 3, т.е. необходимо задать три вопроса,
поскольку количество вопросов – это целое число. Однако представим, что мы
одновременно играем в шесть таких же игр. Тогда необходимо отгадать одну из
возможных комбинаций, которых всего N = n1 · n2·…·n6
= 76 = 117649 < 217 = 131072. Следовательно, для
угадывания всей шестизначной комбинации требуется I = 17 бит информации, т.е.
нужно задать 17 вопросов. В среднем на один элемент (одну игру) приходится 17/3
= 2,833 вопроса, что близко к значению log27. Таким образом,
величина I, определяемая по числу ответов, показывает, сколько в среднем
необходимо сделать парных выборов для установления результата (полного снятия
неопределенности), если опыт повторить многократно
(
log2
7 = 2,807 < log2 8 = 3, т.е. необходимо задать три вопроса,
поскольку количество вопросов – это целое число. Однако представим, что мы
одновременно играем в шесть таких же игр. Тогда необходимо отгадать одну из
возможных комбинаций, которых всего N = n1 · n2·…·n6
= 76 = 117649 < 217 = 131072. Следовательно, для
угадывания всей шестизначной комбинации требуется I = 17 бит информации, т.е.
нужно задать 17 вопросов. В среднем на один элемент (одну игру) приходится 17/3
= 2,833 вопроса, что близко к значению log27. Таким образом,
величина I, определяемая по числу ответов, показывает, сколько в среднем
необходимо сделать парных выборов для установления результата (полного снятия
неопределенности), если опыт повторить многократно
(![]() ).
).
3. Необходимо понимать также, что не всегда с каждым из ответов на вопрос, имеющий только два варианта ответа (будем далее называть такие вопросы бинарными), связан ровно 1 бит информации.
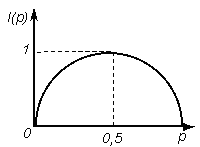
4. Рассмотрим опыт, реализующийся посредством двух случайных событий; поскольку их всего два, очевидно, они являются дополнительными друг другу. Если эти события равновероятны, p1=p2= 1/2, и I = 1 бит, как следует из формулы Хартли и (1.14). Однако, если их вероятности различны: p1 = p, и, согласно p2 = 1 – p, то из (1.14)
I(p) = – p·log2 p – (1 – p)· log2 (1 – p)
Легко показать, что при p![]() 0 и
при p
0 и
при p![]() 1 функция
I(p)
1 функция
I(p)![]() 0.
Ситуация может быть проиллюстрирована графиком, из которого, в частности,
видно, что кривая симметрична относительно p = 0,5 и достигает максимума при
этом значении. Если теперь считать, что событие 1 – это утвердительный ответ на
бинарный вопрос, а событие 2 – отрицательный, то мы приходим к заключению:
0.
Ситуация может быть проиллюстрирована графиком, из которого, в частности,
видно, что кривая симметрична относительно p = 0,5 и достигает максимума при
этом значении. Если теперь считать, что событие 1 – это утвердительный ответ на
бинарный вопрос, а событие 2 – отрицательный, то мы приходим к заключению:
Ответ на бинарный вопрос может содержать не более 1 бит информации; информация равна 1 бит только для равновероятных ответов; в остальных случаях она меньше 1 бита.
Пример 5. При угадывании результата броска игральной кости задается вопрос "Выпало 6?". Какое количество информации содержит ответ?
p = 1/6 , 1 – p = 5/6, следовательно, из (1.14)
I = – 1/6 · log2 1/6 – 5/6 · log2
5/6 ![]() 0,65
бит < 1 бита.
0,65
бит < 1 бита.
Из этого примера видна также ошибочность утверждения, встречающегося в некоторых учебниках информатики, что 1 бит является минимальным количеством информации – никаких оснований для такого утверждения в теории информации нет.
5.
Формула (1.14) приводит
нас еще к одному выводу. Пусть некоторый опыт имеет два исхода A и B, причем pA
= 0,99 , а pB = 0,01. В случае исхода A мы получим количество информации
IA= –log20,99=0,0145 бит. В случае исхода B количество информации оказывается равным
IB= –log20,01=6,644 бит. Другими словами, больше информации связано с теми
исходами, которые менее вероятны. Действительно, то, что наступит именно A, мы
почти наверняка знали и до опыта; поэтому реализация такого исхода очень мало
добавляет к нашей осведомленности. Наоборот, исход B – весьма редкий;
информации с ним связано больше (осуществилось трудно ожидаемое событие).
Однако такое большое количество информации мы будем при повторах опыта получать
редко, поскольку мала вероятность B. Среднее же количество информации равно
I = 0,99·IA + 0,01·IB ![]() 0,081 бит.
0,081 бит.
Нами рассмотрен
вероятностный подход к определению количества информации. Он не является
единственным. Как будет показано далее, количество информации можно связать с
числом знаков в дискретном сообщении – такой способ измерения называется
объемным. Можно доказать, что при любом варианте кодирования информации
Iвер ![]() Iоб.
Iоб.
Объективность информации. При использовании людьми одна и та же информация может иметь различную оценку с точки зрения значимости (важности, ценности). Определяющим в такой оценке оказывается содержание (смысл) сообщения для конкретного потребителя. Однако при решении практических задач технического характера содержание сообщения может не играть роли. Например, задача телеграфной (и любой другой) линии связи является точная и безошибочная передача сообщения без анализа того, насколько ценной для получателя оказывается связанная с ним информация. Техническое устройство не может оценить важности информации – его задача без потерь передать или сохранить информацию. Выше мы определили информацию как результат выбора. Такое определение не зависит от того, кто и каким образом осуществляет выбор, а связанная с ним количественная мера информации – одинаковой для любого потребителя. Следовательно, появляется возможность объективного измерения информации, при этом результат измерения – абсолютен. Это служит предпосылкой для решения технических задач. Нельзя предложить абсолютной и единой для всех меры ценности информации. С точки зрения формальной информации страница из учебника информатики или из романа "Война и мир" и страница, записанная бессмысленными значками, содержат одинаковое количество информации. Количественная сторона информации объективна, смысловая – нет. Однако, жертвуя смысловой (семантической) стороной информации, мы получаем объективные методы измерения ее количества, а также обретаем возможность описывать информационные процессы математическими уравнениями. Это является приближением и в то же время условием применимости законов теории информации к анализу и описанию информационных процессов.
Информация и знание. На бытовом уровне, в науках социальной направленности, например в педагогике "информация" отождествляется с "информированностью", т.е. человеческим знанием, которое, в свою очередь, связано с оценкой смысла информации. В теории информации же, напротив, информация является мерой нашего незнания чего-либо (но что в принципе может произойти); как только это происходит и мы узнаем результат, информация, связанная с данным событием, исчезает. Состоявшееся событие не несет информации, поскольку пропадает его неопределенность (энтропия становится равной нулю), и согласно (1.13) I = 0.
Последние два замечания представляются весьма важными, поскольку недопонимание указанных в них обстоятельств порождает попытки применения законов теории информации в тех сферах, где условия ее применимости не выполнены. Это, в свою очередь, порождает отрицательные результаты, которые служат причиной разочарования в самой теории. Однако любая теория, в том числе и теория информации, справедлива лишь в рамках своих исходных ограничений.
На следующем шаге мы рассмjтрим взаимосвязь информации и алфавита.
