На этом шаге рассмотрим типичные приемы моделирования физической базы данных в UML.
Логическая схема базы данных охватывает словарь хранимых данных системы вместе с семантикой их связей. Физически все эти сущности сохраняются в базе данных – либо в реляционной, либо в объектно-ориентированной, либо в гибридной (объектно-реляционной) – для последующего извлечения. UML так же хорошо приспособлен к моделированию физических баз данных, как и к моделированию их логических схем.
Отображение логической схемы базы данных на объектно-ориентированную базу достаточно прямолинейно, поскольку даже сложные цепочки наследования могут быть сохранены без какого-либо преобразования. Однако отобразить логическую схему на реляционную базу не так просто. Если имеет место наследование, приходится принимать решения относительно того, как отображать классы на таблицы. Обычно применяется либо одна из трех ниженазванных стратегий, либо их комбинация:
- Спуск (push down) – определяется отдельная таблица для каждого класса. Это простой, но примитивный подход, поскольку он вызывает проблемы сопровождения при добавлении новых дочерних классов или модификации существующих родительских.
- Подъем (pull up) – все цепочки наследования свертываются так, что реализации любого класса в иерархии имеют одинаковое состояние. Недостаток в том, что во многих экземплярах приходится хранить избыточную информацию.
- Расщепление таблиц (split tables) – данные родительского и дочернего класса разносятся по разным таблицам. Такой подход лучше отображает структуру наследования, но его недостаток состоит в том, что для доступа к данным приходится соединять многие таблицы.
Проектируя физическую базу данных, необходимо также решить, как следует отображать операции, определенные в логической схеме. Объектно-ориентированные базы данных обеспечивают достаточно прозрачное отображение, но что касается реляционных, здесь приходится решать, как реализовать эти логические операции. Опять же, существует несколько вариантов:
- Простые операции создания, выборки, обновления и удаления реализуются стандартными вызовами SQL или ODBC.
- Более сложное поведение (такое как бизнес-правила) отображается на триггеры и хранимые процедуры.
С учетом приведенных соображений для моделирования физической базы данных необходимо:
- Идентифицировать присутствующие в модели классы, которые представляют логическую схему базы данных.
- Выбрать стратегию отображения этих классов на таблицы. Следует рассмотреть и физическое распределение баз данных. Необходимо проанализировать физическое размещение данных в системе – от этого тоже зависит выбор стратегии.
- Создать диаграмму артефактов для визуализации, специфицирования, конструирования и документирования отображения, в которой артефакты имеют стереотип таблицы.
- По возможности использовать инструментальные средства для преобразования логической схемы в физическую.
На рис. 1 показан набор таблиц базы данных, взятых из информационной системы учебного заведения.
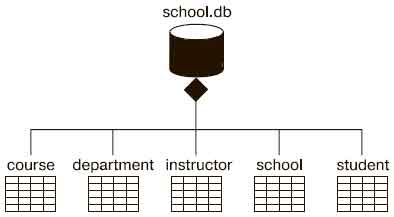
Рис.1. Моделирование физической базы данных
Вы видите одну базу – school.db, изображенную в виде артефакта со стереотипом database. Она состоит из пяти таблиц: student (студент), class (класс), instructor (инструктор), department (отдел) и course (курс). В соответствующей логической схеме базы данных нет наследования, поэтому отобразить ее на физическую несложно.
Хотя в данном примере это не показано, вы можете специфицировать содержимое каждой таблицы. Артефакты могут иметь атрибуты, поэтому общая идиома при моделировании физической базы данных заключается в использовании атрибутов для специфицирования столбцов каждой таблицы.
Аналогичным образом артефакты могут иметь операции, которые позволяют отображать хранимые процедуры.
На следующем шаге рассмотрим типичные приемы моделирования адаптируемых систем в UML.
