На этом шаге мы рассмотрим представление грамматики в памяти компьютера.
Рассмотрим представление в памяти контекстно-свободной грамматики [1, с.455-457] с помощью плексов.
Плексы (сплетения) - структуры данных, служащие для представления графов, имеющих ребра, принадлежащих нескольким различным семействам [2, с.88]. И.Флорес [3, с.155-174] называет плексы ветвящимися списками, а Д.Кнут [4, с.390-391,500-505] - Списками (с большой буквы!).
Отметим, что плексы широко применяются в трансляторах для отображения деревьев и графов в памяти ЭВМ, так как плексы лучше других типов структур отображают многоуровневые структуры данных в памяти ЭВМ.
Кстати, как заметил П.Холл [5, с.66], "... метод представления с помощью матрицы инцидентности - это разновидность метода плексов!"
Представление грамматики с помощью плексов становится удобным в тех случаях, когда грамматику необходимо рассматривать и обрабатывать путем нисходящего синтаксического анализа. Эффективное представление грамматик в памяти необходимо в связи с тем, что различные варианты правил должны проверяться на их применимость на каждом шаге анализа конструкции фразы.
Представление синтаксиса с помощью графа имеет один существенный недостаток: компьютеры "не умеют читать графы", т.о. перед началом грамматического разбора нужно каким-то образом строить структуры данных, представляющие грамматику.
Мы предполагаем, что грамматика представлена в виде детерминированного множества синтаксических графов (плексов).
Естественный способ представить граф - это ввести узел для каждого символа и связать эти узлы при помощи ссылок. Узлы этой структуры представляют собой объединения, один для терминального, а другой для нетерминального символа грамматики. Первый идентифицируется терминальным символом, который он обозначает, второй - ссылкой на структуру данных, представляющую соответствующий нетерминальный символ. Оба варианта содержат две ссылки: одна указывает на следующий символ, последователь (Suc), а другая связана со списком возможных альтернатив (Alt).
Теперь мы в состоянии привести описание соответствующего типа данных:
typedef int Boolean; typedef struct Header *Hpointer; //Тип: указатель на заглавный узел. typedef struct Node { Node *Suc; Node *Alt; Boolean Terminal; union { char Tsym [33]; Hpointer Nsym; } TR; };
Графически узел можно изобразить так:
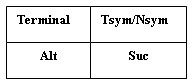
Рис.1. Графическое представление узла
Выясняется, что еще нужен элемент, представляющий пустую последовательность, символ "пусто". Мы обозначим его с помощью терминального элемента Empty.
Структура данных идентифицируется узлом-заголовком, который содержит имя нетерминального символа (цели), к которому относится структура. Заголовок можно использовать для хранения выводимого на печать имени структуры:
//Описание типа заглавного звена. typedef struct Header { Node* Entry; char Sym[33]; };
Пример [6,с.330,с.338]. Изобразим структуру для следующей грамматики:
A ::= x (B),
B ::= AC,
C ::= {+A}.
Здесь +, x, (, ) - терминальные символы, а { и } - принадлежат расширенной БНФ (форма Бэкуса-Наура) и, следовательно, являются метасимволами.
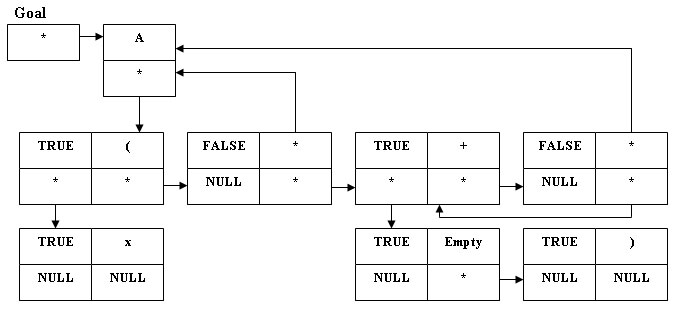
Рис.2. Грамматика
Ясно, что язык, порождаемый из приведенной грамматики, состоит из выражений с операндами x, знаком операции "+" и скобками.
Приведем примеры правильных предложений языка:
x (x) (x+x) ((x))
Программа, производящая грамматический разбор предложения, представленного в виде последовательности символов входного файла, состоит из повторяющегося оператора, описывающего переход от одного узла к следующему узлу [6,с.339]. Она оформлена как процедура, задающая интерпретацию графа; если встречается узел, представляющий нетерминальный символ, то интерпретация графа, на который он ссылается, предшествует завершению интерпретации текущего графа. Следовательно, процедура интерпретации вызывается рекурсивно.
Если текущий символ (Sym) входного файла совпадает с символом в текущем узле структуры данных, то процедура переходит к узлу, на который указывает поле Suc, иначе - к узлу, на который указывает поле Alt:
void Spisok::Parse(Hpointer Goal, Boolean *Match) { Node *s; s = Goal->Entry; do { if ( s->Terminal ) { if (!strcmp(s->TR.Tsym,Sym)) { (*Match) = TRUE; Get_Sym(); } else (*Match) = !(strcmp(s->TR.Tsym,"Empty")); } else Parse (s->TR.Nsym,&(*Match)); if (*Match) s = s->Suc; else s = s->Alt; } while (s!=NULL); } void Spisok::Get_Sym() { char Q; cin >> Q; Sym[0]=Q; Sym[1]='\0'; }
На основе функции Parse можно построить более сложные программы грамматического разбора, которые могут работать с более широкими классами грамматик.
Пример [6, с.339]. Программа грамматического разбора. Программа написана И.А.Лебедевой (февраль 1993 г.).
#include <iostream.h> #include <string.h> #define TRUE 1 #define FALSE 0 typedef int Boolean; typedef struct Header *Hpointer; //Тип: указатель на заглавный узел. typedef struct Node { Node *Suc; Node *Alt; Boolean Terminal; union { char Tsym [33]; Hpointer Nsym; } TR; }; //Описание типа заглавного звена. typedef struct Header { Node* Entry; char Sym[33]; }; class Spisok { private: Hpointer Goal; //Указатель на заглавное звено. char Sym[33]; void Parse(Hpointer, Boolean *); void Get_Sym(); public: Spisok () { Goal = NULL; }; void Postr(); void Prov(); int Razbor(); }; void Spisok::Postr() // Построение синтаксического графа. { Node *UkZv; //Текущий указатель. Node *UkZv1; //Текущий указатель. Goal = new (Header); strcpy(Goal->Sym,"A"); // Goal +-----+ // * ---> | A | // +-----+ // | | // +-----+ // ------------------------------ Goal->Entry = new (Node); UkZv = Goal->Entry; UkZv->Terminal = TRUE; strcpy(UkZv->TR.Tsym,"("); // Goal +-----+ // * ---> | A | // +-----+ // | * | // +--|--+ // | // V // +----+----+ // UkZv |TRUE| ( | // * ---> +----+----+ // | | | // +----+----+ // ------------------------------ UkZv->Alt = new (Node); UkZv1 = UkZv->Alt; UkZv1->Terminal = TRUE; strcpy(UkZv1->TR.Tsym,"x"); UkZv1->Alt = UkZv1->Suc = NULL; // Goal +-----+ // * ---> | A | // +-----+ // | * | // +--|--+ // | // V // +----+----+ // UkZv |TRUE| ( | // * ---> +----+----+ // | * | | // +-|--+----+ // | // V // +----+----+ // UkZv1 |TRUE| x | // * ---> +----+----+ // |NULL|NULL| // +----+----+ // ------------------------------ UkZv->Suc = new (Node); UkZv = UkZv->Suc; UkZv->Terminal = FALSE; UkZv->TR.Nsym = Goal; UkZv->Alt = NULL; // Goal +-----+ // * ---> | A | <---------------+ // +-----+ | // | * | UkZv * | // +--|--+ | | // | | | // V V | // +-----+-----+ +-----+--|--+ // |TRUE | ( | |FALSE| * | // +-----+-----+ +-----+-----+ // | * | * ---->|NULL | | // +--|--+-----+ +-----+-----+ // | // V // +-----+-----+ // UkZv1 |TRUE | x | // * ---> +-----+-----+ // |NULL |NULL | // +-----+-----+ // ----------------------------------------- UkZv->Suc = new (Node); UkZv1 = UkZv->Suc; UkZv1->Terminal = TRUE; strcpy(UkZv1->TR.Tsym,"+"); // Goal +-----+ // * ---> | A | <---------------+ // +-----+ | // | * | UkZv * | UkZv1 * // +--|--+ | | | // | | | | // V V | V // +-----+-----+ +-----+--|--+ +-----+-----+ // |TRUE | ( | |FALSE| * | |TRUE | + | // +-----+-----+ +-----+-----+ +-----+-----+ // | * | * ---->|NULL | * ---->| | | // +--|--+-----+ +-----+-----+ +-----+-----+ // | // V // +-----+-----+ // |TRUE | x | // +-----+-----+ // |NULL |NULL | // +-----+-----+ // ------------------------------------------------------ UkZv1->Suc = new (Node); UkZv1 = UkZv1->Suc; UkZv = UkZv->Suc; UkZv1->Terminal = FALSE; UkZv1->TR.Nsym = Goal; UkZv1->Alt = NULL; UkZv1->Suc = UkZv; //Goal +-----+ // * ->| A | <---------------------------------------------+ // +-----+ <---------------+ | // | * | | UkZv * UkZv1 * | // +--|--+ | | | | // | | | | | // V | V V | // +-----+-----+ +-----+--|--+ +-----+-----+ +-----+--|--+ // |TRUE | ( | |FALSE| * | |TRUE | + | |FALSE| * | // +-----+-----+ +-----+-----+ +-----+-----+ +-----+-----+ // | * | * --->|NULL | * --->| | * --->|NULL | * | // +--|--+-----+ +-----+-----+ +-----+-----+ +-----+--|--+ // | ^ | // V +-----------------+ // +-----+-----+ // |TRUE | x | // +-----+-----+ // |NULL |NULL | // +-----+-----+ // -------------------------------------------------------------- UkZv->Alt = new (Node); UkZv = UkZv->Alt; UkZv->Terminal = TRUE; strcpy(UkZv->TR.Tsym,"Empty"); UkZv->Alt = NULL; //Goal +-----+ // * ->| A | <---------------------------------------------+ // +-----+ <---------------+ | // | * | | UkZv1 * | // +--|--+ | | | // | | | | // V | V | // +-----+-----+ +-----+--|--+ +-----+-----+ +-----+--|--+ // |TRUE | ( | |FALSE| * | |TRUE | + | |FALSE| * | // +-----+-----+ +-----+-----+ +-----+-----+ +-----+-----+ // | * | * --->|NULL | * --->| * | * --->|NULL | * | // +--|--+-----+ +-----+-----+ +--|--+-----+ +-----+--|--+ // | | ^ | // | | +-----------------+ // V V // +-----+-----+ +-----+-----+ // |TRUE | x | UkZv |TRUE |Empty| // +-----+-----+ * --> +-----+-----+ // |NULL |NULL | |NULL | | // +-----+-----+ +-----+-----+ // -------------------------------------------------------------- UkZv->Suc = new (Node); UkZv = UkZv->Suc; UkZv->Terminal = TRUE; strcpy(UkZv->TR.Tsym,")"); UkZv->Alt = UkZv->Suc = NULL; //Goal +-----+ // * ->| A | <---------------------------------------------+ // +-----+ <---------------+ | // | * | | UkZv1 * | // +--|--+ | | | // V | V | // +-----+-----+ +-----+--|--+ +-----+-----+ +-----+--|--+ // |TRUE | ( | |FALSE| * | |TRUE | + | |FALSE| * | // +-----+-----+ +-----+-----+ +-----+-----+ +-----+-----+ // | * | * --->|NULL | * --->| * | * --->|NULL | * | // +--|--+-----+ +-----+-----+ +--|--+-----+ +-----+--|--+ // | | ^ | // | | +-----------------+ // V V // +-----+-----+ +-----+-----+ +-----+-----+ // |TRUE | x | |TRUE |Empty| |TRUE | ) | // +-----+-----+ +-----+-----+ +-----+-----+ // |NULL |NULL | |NULL | * --->|NULL |NULL | // +-----+-----+ +-----+-----+ +-----+-----+ // ^ // | // UkZv * } void Spisok::Prov() // Проверка графа. { Node *A, *C; //Рабочие переменные. cout << "Элементарная проверка построенного графа...\n"; A = Goal->Entry; cout << A->TR.Tsym << " "; cout << A->Suc->Suc->TR.Tsym << " "; cout << A->Suc->Suc->Alt->Suc->TR.Tsym << " "; cout << A->Alt->TR.Tsym << " "; C = A->Suc->TR.Nsym->Entry; cout << C->TR.Tsym << endl; cout << "Проверка окончена!\n"; } int Spisok::Razbor() // Синтаксический разбор. { Boolean Rez = FALSE; // Приступим к грамматическому разбору. cout << "Вводите строку...\n"; cout << "Конец ввода - символ \"точка\".\n"; Get_Sym(); Parse(Goal,&Rez); cout << endl; if ((Rez) && !strcmp(Sym,".")) return 1; else return 0; } void Spisok::Get_Sym() { char Q; cin >> Q; Sym[0]=Q; Sym[1]='\0'; } void Spisok::Parse(Hpointer Goal, Boolean *Match) { Node *s; s = Goal->Entry; do { if ( s->Terminal ) { if (!strcmp(s->TR.Tsym,Sym)) { (*Match) = TRUE; Get_Sym(); } else (*Match) = !(strcmp(s->TR.Tsym,"Empty")); } else Parse (s->TR.Nsym,&(*Match)); if (*Match) s = s->Suc; else s = s->Alt; } while (s!=NULL); } void main() { Spisok A; // Построение синтаксического графа. A.Postr(); A.Prov(); if (A.Razbor()) cout << "Все хорошо!"; else cout << "Ошибка!"; }
(1) Трамбле Ж., Соренсон П. Введение в структуры данных. - М.: Машиностроение, 1982. - 784 с.
(2) Разумов О.С. Организация данных в вычислительных системах. - М.: Статистика, 1978. - 184 с.
(3) Флорес И. Структуры и управление данными. - М.: Финансы и статистика, 1982. - 319 с.
(4) Кнут Д. Искусство программирования для ЭВМ. Т.1: Основные алгоритмы. - M.: Мир, 1976. - 736 с.
(5) Холл П. Вычислительные структуры. Введение в нечисленное программирование. - М.: Мир, 1978. - 214 с.
(6) Вирт H. Алгоритмы + структуры данных = программы. - М.: Мир, 1985. - 406 с.
Со следующего шага мы начнем знакомиться со способами обхода графов.
