На этом шаге мы рассмотрим особенности и ограничения этой кластеризации.
Результатом агломеративной кластеризации является иерархическая кластеризация (hierarchical clustering). Кластеризация выполняется итеративно, и каждая точка совершает путь от отдельной точки-кластера до участника итогового кластера. На каждом промежуточном шаге происходит кластеризация данных (с разным количеством кластеров). Иногда полезно сразу взглянуть на все возможные кластеризации. Следующий пример (рисунок 1) показывает наложение всех возможных кластеризаций, показанных на рисунке 1 101 шага и дает некоторое представление о том, как каждый кластер распадается на более мелкие кластеры:
[In 62]:
mglearn.plots.plot_agglomerative()
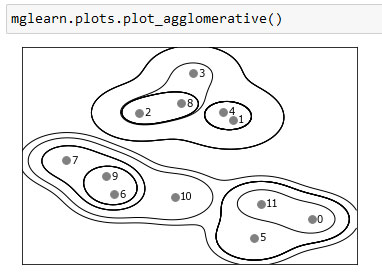
Рис.1. Иерархическое присвоение кластеров (показаны в виде линий), полученное с помощью алгоритма агломеративной кластеризации, точки данных пронумерованы (см. рисунок 2)
Хотя эта визуализация дает достаточно детализированное представление о результатах иерархической кластеризации, она опирается на двумерную природу данных и не может быть использована для наборов данных, которые имеют более двух характеристик. Однако есть еще один инструмент для визуализации результатов иерархической кластеризации, называемый дендрограммой (dendrogram) и позволяющий обрабатывать многомерные массивы данных.
К сожалению, на данный момент в scikit-learn нет инструментов, позволяющих рисовать дендрограммы. Однако вы легко можете создать их с помощью SciPy. По сравнению с алгоритмами кластеризации scikit-learn алгоритмы кластеризации SciPy имеют немного другой интерфейс. В SciPy используется функция, которая принимает массив данных X в качестве аргумента и вычисляет массив связей (linkage array) с записанными сходствами между кластерами. Затем мы можем скормить этот массив функции SciPy dendrogram(), чтобы построить дендрограмму (рисунок 2):
[In 63]: # импортируем функцию dendrogram и функцию кластеризации ward из SciPy from scipy.cluster.hierarchy import dendrogram, ward X, y = make_blobs(random_state=0, n_samples=12) # применяем кластеризацию ward к массиву данных X # функция SciPy ward возвращает массив с расстояниями # вычисленными в ходе выполнения агломеративной кластеризации linkage_array = ward(X) # теперь строим дендрограмму для массива связей, содержащего расстояния # между кластерами dendrogram(linkage_array) # делаем отметки на дереве, соответствующие двум или трем кластерам ax = plt.gca() bounds = ax.get_xbound() ax.plot(bounds, [7.25, 7.25], '--', c='k') ax.plot(bounds, [4, 4], '--', c='k') ax.text(bounds[1], 7.25, ' два кластера', va='center', fontdict={'size': 15}) ax.text(bounds[1], 4, ' три кластера', va='center', fontdict={'size': 15}) plt.xlabel("Индекс наблюдения") plt.ylabel("Кластерное расстояние")
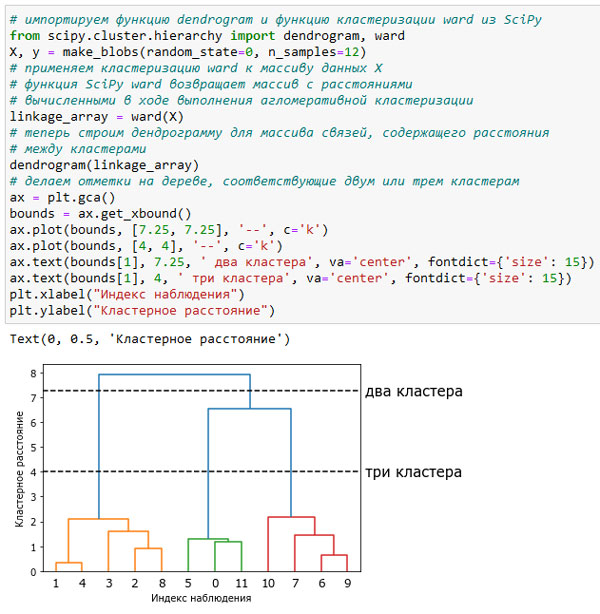
Рис.2. Дендрограмма для кластеризации, показанной на рисунке 1, линии обозначают расщепления на два и три кластера
Точки данных показаны в нижнеи части дендрограммы (пронумерованы от 0 до 11). Затем строится дерево с этими точками (представляющими собой кластеры-точки) в качестве листьев, и для каждых двух объединенных кластеров добавляется новый узел-родитель.
Чтение дендрограммы происходит снизу вверх. Точки данных 1 и 4 объединяются первыми (как вы уже могли видеть на рисунке 1 101 шага). Затем в кластер объединяются точки 6 и 9 и т.д. На самом верхнем уровне остаются две ветви, одна ветвь состоит из точек 11, 0, 5, 10, 7, 6 и 9, а вторая - из точек 1, 4, 3, 2 и 8. Они соответствуют двум крупнейшим кластерам.
Ось у в дендрограмме указывает не только момент объединения двух кластеров в ходе работы алгоритма агломеративной кластеризации. Длина каждой ветви показывает, насколько далеко друг от друга находятся объединенные кластеры. Самыми длинными ветвями в этой дендрограмме являются три линии, отмеченные пунктирной чертой с надписью "три кластера". Тот факт, что эти линии являются самыми длинными ветвями, указывает на то, что переход от трех кластеров к двум сопровождался объединением некоторых сильно удаленных друг от друга точек. Мы снова видим это в самой верхней части графика, когда объединение двух оставшихся кластеров в единый кластер подразумевает относительно большое расстояние между точками.
К сожалению, алгоритм агломеративной кластеризации по-прежнему не в состоянии обработать сложные данные типа набора two_moons. Чего нельзя сказать о DBSCAN, следующем алгоритме, который мы рассмотрим.
На следующем шаге мы рассмотрим алгоритм DBSCAN.
