На этом шаге мы рассмотрим особенности использования этого алгоритма.
Еще один очень полезный алгоритм кластеризации - DBSCAN (density-based spatial clustering of applications with noise - плотностный алгоритм кластеризации пространственных данных с присутствием шума). Основные преимущества алгоритма DBSCAN заключаются в том, что пользователю не нужно заранее задавать количество кластеров, алгоритм может выделить кластеры сложной формы и способен определить точки, которые не принадлежат какому-либо кластеру. DBSCAN работает немного медленнее, чем алгоритм агломеративной кластеризации и алгоритм k-средних, но также может масштабироваться на относительно большие наборы данных.
DBSCAN определяет точки, расположенные в "густонаселенных" областях пространства характеристик, когда многие точки данных расположены близко друг к другу. Эти области называются плотными (dense) областями пространства характеристик. Идея алгоритма DBSCAN заключается в том, что кластеры образуют плотные области данных, которые отделены друг от друга относительно пустыми областями.
Точки, находящиеся в плотной области, называются ядровыми примерами (core samples) или ядровыми точками (corepoints). Алгоритм DBSCAN имеет два параметра: min_samples и eps. Если по крайней мере min_samples точек находятся в радиусе окрестности eps рассматриваемой точки, то эта точка классифицируется как ядровая. Ядровые точки, расстояния между которыми не превышают радиус окрестности eps, помещаются алгоритмом DBSCAN в один и тот же кластер.
На старте алгоритм выбирает произвольную точку. Затем он находит все точки, удаленные от стартовой точки на расстоянии, не превышающем радиус окрестности eps. Если множество точек, находящихся в пределах радиуса окрестности eps, меньше значения min_samples, стартовая точка помечается как (noise), это означает, что она не принадлежит какому-либо кластеру. Если это множество точек больше значения min_samples, стартовая точка помечается как ядровая и ей назначается метка нового кластера. Затем посещаются все соседи этой точки (находящиеся в пределах eps). Если они еще не были присвоены кластеру, им присваивается метка только что созданного кластера. Если они являются ядровыми точками, поочередно посещаются их соседи и т.д. Кластер растет до тех пор, пока не останется ни одной ядерной точки в пределах радиуса окрестности eps. Затем выбирается другая точка, которая еще не была посещена, и повторяется та же самая процедура.
В итоге получаем три вида точек:
- ядровые точки,
- точки, которые находятся в пределах радиуса окрестности eps ядровых точек (так называемые пограничные точки или boundary points) и
- шумовые точки.
Давайте применим алгоритм DBSCAN к синтетическому набору данных, который мы использовали для демонстрации агломеративной кластеризации. Как и алгоритм агломеративной кластеризации, алгоритм DBSCAN не позволяет получать прогнозы для новых тестовых данных, поэтому мы воспользуемся методом fit_predict(), чтобы сразу выполнить кластеризацию и возвратить метки кластеров:
[In 64]: from sklearn.cluster import DBSCAN from sklearn.datasets import make_blobs X, y = make_blobs(random_state=0, n_samples=12) dbscan = DBSCAN() clusters = dbscan.fit_predict(X) print("Принадлежность к кластерам:\n{}".format(clusters)) Принадлежность к кластерам: [-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]
Можно увидеть, что всем точкам данных была присвоена метка -1, которая обозначает шум. Полученная сводка является результатом применения значений eps и min_samples, установленных по умолчанию и не настроенных для работы с небольшими синтетическими наборами данных. Принадлежность к кластерам для различных значений min_samples и eps показана в сводке и визуализирована на рисунке 1:
[In 65]:
mglearn.plots.plot_dbscan()
min_samples: 2 eps: 1.000000 cluster: [-1 0 0 -1 0 -1 1 1 0 1 -1 -1]
min_samples: 2 eps: 1.500000 cluster: [0 1 1 1 1 0 2 2 1 2 2 0]
min_samples: 2 eps: 2.000000 cluster: [0 1 1 1 1 0 0 0 1 0 0 0]
min_samples: 2 eps: 3.000000 cluster: [0 0 0 0 0 0 0 0 0 0 0 0]
min_samples: 3 eps: 1.000000 cluster: [-1 0 0 -1 0 -1 1 1 0 1 -1 -1]
min_samples: 3 eps: 1.500000 cluster: [0 1 1 1 1 0 2 2 1 2 2 0]
min_samples: 3 eps: 2.000000 cluster: [0 1 1 1 1 0 0 0 1 0 0 0]
min_samples: 3 eps: 3.000000 cluster: [0 0 0 0 0 0 0 0 0 0 0 0]
min_samples: 5 eps: 1.000000 cluster: [-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]
min_samples: 5 eps: 1.500000 cluster: [-1 0 0 0 0 -1 -1 -1 0 -1 -1 -1]
min_samples: 5 eps: 2.000000 cluster: [-1 0 0 0 0 -1 -1 -1 0 -1 -1 -1]
min_samples: 5 eps: 3.000000 cluster: [0 0 0 0 0 0 0 0 0 0 0 0]
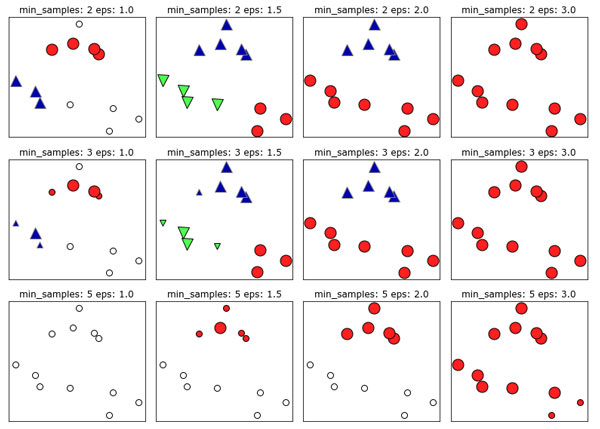
Рис.1. Принадлежность к кластерам, вычисленная с помощью алгоритма DBSCAN при различных значениях min_samples и eps
На этом графике точки, которые принадлежат кластерам, окрашены сплошным цветом, а шумовые точки - белым цветом. Ядровые точки показаны в виде больших маркеров, тогда как пограничные точки отображаются в виде небольших маркеров. Увеличение значения eps (слева направо на рисунке) означает включение большего количества точек в кластер. Это приводит к росту размеров кластеров, но также может привести к тому, что несколько кластеров будут объединены в один. Увеличение значения min_samples (сверху вниз на рисунке) означает уменьшение количества ядерных точек и увеличение количества шумовых точек.
Параметр eps чуть более важен, поскольку он определяет, что подразумевается под "близостью" точек друг к другу. Очень маленькое значение eps будет означать отсутствие ядерных точек и может привести к тому, что все точки будут помечены как шумовые. Очень большое значение eps приведет к тому, что все точки сформируют один кластер.
Значение min_samples главным образом определяет, будут ли точки, расположенные в менее плотных областях, помечены как выбросы или как кластеры. Если увеличить значение min_samples, все, что могло бы стать кластером с количеством точек, не превышающим min_samples, будет помечено как шум. Поэтому значение min_samples задает минимальный размер кластера. Это очень четко можно увидеть на рисунке 1, когда мы увеличиваем значение min_samples с 3 до 5 при eps=1.5. При min_samples =3 получаем три кластера: первый кластер состоит из четырех точек, второй - из пяти точек и третий - из трех точек. При min_samples=5 два кластера меньшего размера (с тремя и четырьмя точками) теперь помечены как шум и остается лишь кластер с пятью точками.
Несмотря на то что в алгоритме DBSCAN не нужно явно указывать количество кластеров, значение eps неявно задает количество выделяемых кластеров. Иногда подобрать оптимальное значение eps становится проще после масштабирования данных с помощью StandardScaler или MinMaxScaler, так как использование этих методов масштабирования гарантирует, что все характеристики будут иметь одинаковый масштаб.
Рисунок 2 показывает результат выполнения алгоритма DBSCAN для наборе данных two_moons. Алгоритм фактически находит две группы данных в форме полумесяцев и разделяет их, используя настройки по умолчанию:
[In 66]: X, y = make_moons(n_samples=200, noise=0.05, random_state=0) # масштабируем данные так, чтобы получить нулевое среднее и единичную дисперсию scaler = StandardScaler() scaler.fit(X) X_scaled = scaler.transform(X) dbscan = DBSCAN() clusters = dbscan.fit_predict(X_scaled) # выводим принадлежность к кластерам plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=clusters, cmap=mglearn.cm2, s=60) plt.xlabel("Признак 0") plt.ylabel("Признак 1")
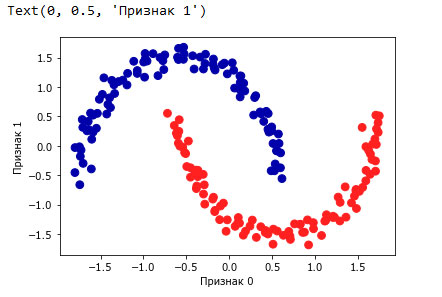
Рис.2. Принадлежность к кластерам, вычисленная с помощью алгоритма DBSCAN, использовалось значение по умолчанию eps=0.5
Поскольку алгоритм выделил нужное количество кластеров (два), настройки параметров, похоже, работают хорошо. Если мы уменьшим значение eps до 0.2 (значение по умолчанию 0.5), мы получим восемь кластеров, что явно слишком много. Увеличение eps до 0.7 даст один кластер.
Используя DBSCAN, будьте осторожны при работе с возвращаемыми номерами кластеров. Использование -1 для обозначения шума может привести к неожиданным эффектам, если метки кластеров будут использоваться для индексирования другого массива.
На следующем шаге мы проведем сравнение и дадим оценку качества алгоритмов кластеризации.
