На этом шаге мы рассмотрим первый пример с использованием технологии CUDA.
Для эффективности вычисления используется разделяемая память, так как разделяемая память расположена в мультипроцессорах. Так же для удобства и быстроты вычислений используется двумерная матрица сетки блоков и двумерная матрица нитей блоков, так как одним из множителей является матрица.
Всю работу с технологией CUDA можно представить следующим алгоритмом:
- Выделение памяти;
- Копирование данных из памяти, расположенной в CPU, в память, расположенной в GPU;
- Осуществление запуска ядер-функций;
- Копирование результатов из памяти GPU в память CPU;
- Освобождение памяти в GPU.
Здесь и далее будем описывать каждый из этих пунктов.
- Выделение памяти.
double *d_A, *d_B, *d_C; cudaMalloc((void **) &d_A, dimsA.x * dimsA.y * sizeof(double)); cudaMalloc((void **) &d_B, dimsB.x * dimsB.y * sizeof(double)); cudaMalloc((void **) &d_C, dimsC.x * dimsC.y * sizeof(double));
Функция cudaMalloc принимает 2 параметра: 1 - указатель на указатель на указатель места памяти, где выделяется память, 2 - сколько байт нужно выделить для хранения данных.
- Копирование данных из памяти CPU в память GPU
cudaMemcpy(d_A, h_A, dimsA.x * dimsA.y * sizeof(double), cudaMemcpyHostToDevice); cudaMemcpy(d_B, h_B, dimsB.x * dimsB.y * sizeof(double), cudaMemcpyHostToDevice);
Функция cudaMemcpy принимает 4 параметра: 1 - приемщик, 2 - источник, 3 - сколько байт нужно скопировать, 4 - одна из констант. В данном случае это константа cudaMemcpyHostToDevice, так как нужно скопировать с CPU на GPU.
- Осуществление запуска ядер-функций.
matrixVectorMulCUDA<<< grid, threads >>>(d_A, d_B, d_C, dimsA.x, dimsB.x);
Данное ядро принимает 4 параметра: 1 - матрица, 2 - вектор, 3 - размерность матрицы, 4 - размерность вектора.
- Копирование результатов из памяти GPU в память CPU.
cudaMemcpy(h_C, d_C, dimsC.x * dimsC.y * sizeof(double), cudaMemcpyDeviceToHost);
Для копирования из памяти GPU в CPU используется также функция cudaMalloc, различия только в 4 параметре. Его значение должно быть равно cudaMemcpyDeviceToHost.
- Освобождение памяти в GPU.
cudaFree(d_A); cudaFree(d_B); cudaFree(d_C); cudaDeviceReset ();
Функция cudaFree принимает 1 параметр: указатель на место памяти, которое нужно освободить.
Ниже приведем реализацию ядра.
const int BLOCK_SIZE = 16; __global__ void matrixVectorMulCUDA(double *A, double *B, double *C, int wA, int wB){ int bx = blockIdx.x; int by = blockIdx.y; int tx = threadIdx.x; int ty = threadIdx.y; int aBegin = wA * BLOCK_SIZE * by; int aEnd = aBegin + wA - 1; int aStep = BLOCK_SIZE; int bBegin = BLOCK_SIZE * bx; int bStep = BLOCK_SIZE * wB; double Csub = 0; for (int a = aBegin, b = bBegin; a <= aEnd; a += aStep, b += bStep) { __shared__ double As[BLOCK_SIZE][BLOCK_SIZE]; __shared__ double Bs[BLOCK_SIZE][BLOCK_SIZE]; As[ty][tx] = A[a + wA * ty + tx]; Bs[ty][tx] = B[b + wB * ty + tx]; __syncthreads(); for (int k = 0; k < BLOCK_SIZE; ++k) { Csub += As[ty][k] * Bs[k][tx]; } __syncthreads(); } int c = wB * BLOCK_SIZE * by + BLOCK_SIZE * bx; C[c + wB * ty + tx] = Csub; }
Стоит заметить, что после копирования в разделяемую память следует производить синхронизацию нитей для дальнейших расчетов, так как возможно не все нити успели произвести копирование в разделяемую память.
Заметим, что данная операция уже реализована в CUDA и она расположена в библиотеке cuBLAS.
Такой операции соответствует функция cublasDgemv. Перед тем, как использовать эту функцию, нужно также выделить память на устройстве, но также нужно создать так называемый handle. Он нужен для того, чтобы мы могли использовать данную функцию для конкретного устройства. Для каждого устройства нужно создавать свой handle.
Создать handle можно с помощью функции:
cublasCreate(&handle); ,
Для удаления handle нужно использовать функцию:
cublasDestroy(handle); ,
Для копирования значений в память устройства, используют специальные функции. Приведем некоторые из них:
cublasSetMatrix (n, n, sizeof(*mA), mA, n, dev_mA, n); cublasSetVector (n, sizeof(*V), V, 1, dev_V, 1);
Аналогично, для получения значений так же используют специальную функцию:
cublasGetVector(n, sizeof(*Result), dev_Result, 1, Result, 1);
Приведем ниже результаты времени выполнения созданных приложений.
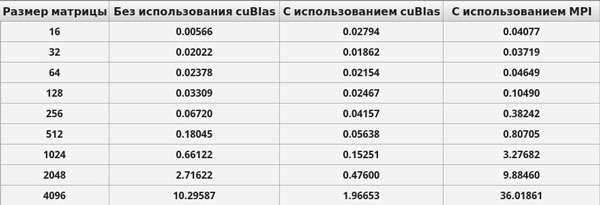
Рис. 1. Результаты вычислений произведения матрицы на вектор на персональном комьютере (время выполнения приведено в милисекундах)
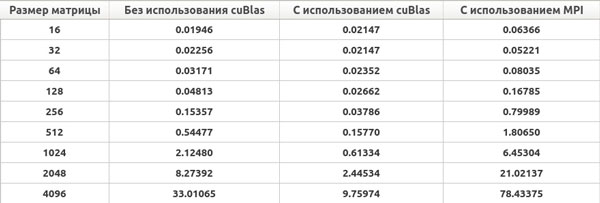
Рис. 2. Результаты вычислений произведения матрицы на вектор на ноутбуке (время выполнения приведено в милисекундах)
На следующем шаге мы продолжим рассмотрение примеров.
