На этом шаге мы рассмотрим второй пример с использованием технологии CUDA.
Так же, как в предыдущем примере, опишем каждый из пунктов. Так как данная программа по своей структуре практически ничем не отличается от программы из предыдущего примера, то приведем только основные различия в каждом пункте.
- Выделение памяти.
unsigned int matrixSize = size * size * sizeof(double); double *d_A, *d_B, *d_C; cudaMalloc ((void **) &d_A, matrixSize); cudaMalloc ((void **) &d_B, matrixSize); cudaMalloc ((void **) &d_C, matrixSize);
- Копирование данных из памяти CPU в память GPU.
cudaMemcpy (d_A, h_A, matrixSize, cudaMemcpyHostToDevice); cudaMemcpy (d_B, h_B, matrixSize, cudaMemcpyHostToDevice);
- Осуществление запуска ядер-функций.
matrixMulCUDA<<< grid, threads >>>(d_A, d_B, d_C, size, size);
- Копирование результатов из памяти GPU в память CPU.
cudaMemcpy (h_C, d_C, matrixSize, cudaMemcpyDeviceToHost);
- Освобождение памяти в GPU.
cudaFree (d_A); cudaFree (d_B); cudaFree (d_C); cudaDeviceReset ();
Само ядро по своей структуре отличается от ядра из предыдущего примера только заголовком:
__global__ void matrixMulCUDA (double *A, double *B, double *C, int wA, int wB);
Данная операция также уже реализована в CUDA и она расположена в той же библиотеке cuBLAS.Такой операции соответствует функция cublasDgemm. Для записи данных используется все та же функция cublasSetMatrix, а для получения используется функция cublasGetMatrix.
Весь проект можно взять здесь.
Приведем ниже результаты времени выполнения созданных приложений.
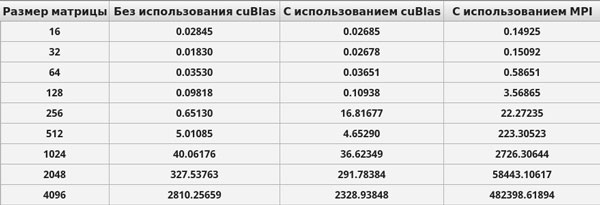
Рис. 1. Результаты вычислений произведения матрицы на матрицу на персональном комьютере (время выполнения приведено в милисекундах)
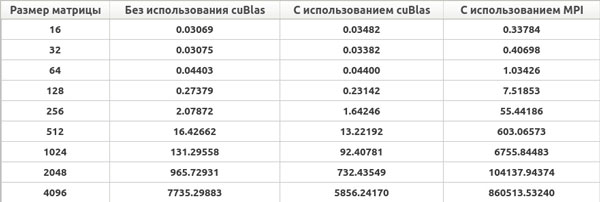
Рис. 2. Результаты вычислений произведения матрицы на матрицу на ноутбуке (время выполнения приведено в милисекундах)
На следующем шаге мы рассмотрим еще один пример.
