На этом шаге мы рассмотрим алгоритм построения такого дерева.
Давайте рассмотрим процесс построения дерева решений для двумерного классификационного набора данных, показанного на рисунке 1. Набор данных состоит из точек, обозначаемых маркерами двух типов. Каждому типу маркера соответствует свой класс, на каждый класс приходится по 75 точек данных. Назовем этот набор данных two_moons.
[In 2]:
mglearn.plots.plot_tree_progressive()
Рис.1. Набор данных two_moons, по которому будет построено дерево решений
Построение дерева решений означает построение последовательности правил "если... то...", которая приводит нас к истинному ответу максимально коротким путем. В машинном обучении эти правила называются тестами (tests). Не путайте их с тестовым набором, который мы используем для проверки обобщающей способности нашей модели. Как правило, данные бывают представлены не только в виде бинарных признаков да/нет, как в примере с животными, но и в виде непрерывных признаков, как в двумерном наборе данных, показанном на рисунке 1. Тесты, которые используются для непрерывных данных имеют вид "Признак i больше значения а?"
Чтобы построить дерево, алгоритм перебирает все возможные тесты и находит тот, который является наиболее информативным с точки зрения прогнозирования значений целевой переменной. Рисунок 2 показывает первый выбранный тест.

Рис.2. Граница принятия решений, полученная с помощью дерева глубиной 1 (сверху) и соответствующее дерево решений (снизу)
Разделение набора данных по горизонтали в точке х[1]=0.0596 дает наиболее полную информацию. Оно лучше всего разделяет точки класса 0 от точек класса 1. Верхний узел, также называемый корнем (root), представляет собой весь набор данных, состоящий из 50 точек, принадлежащих к классу 0, и 50 точек, принадлежащих к классу 1. Разделение выполняется путем тестирования х[1]<=0.0596, обозначенного черной линией. Если тест верен, точка назначается левому узлу, который содержит 2 точки, принадлежащие классу 0, и 32 точки, принадлежащие классу 1. В противном случае точка будет присвоена правому узлу, который содержит 48 точек, принадлежащих классу 0, и 18 точек, принадлежащих классу 1. Эти два узла соответствуют верхней и нижней областям, показанным на рисунке 2. Несмотря на то что первое разбиение довольно хорошо разделило два класса, нижняя область по-прежнему содержит точки, принадлежащие к классу 0, а верхняя область по-прежнему содержит точки, принадлежащие к классу 1. Мы можем построить более точную модель, повторяя процесс поиска наилучшего теста в обоих областях. Рисунок 3 показывает, что следующее наиболее информативное разбиение для левой и правой областей основывается на х[0].
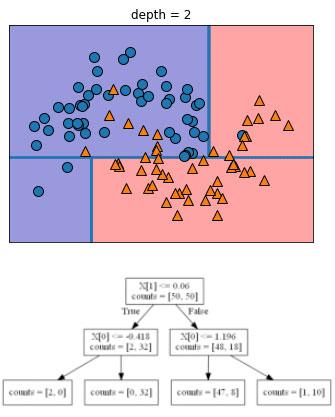
Рис.3. Граница принятия решений, полученная с помощью дерева глубиной 2 (сверху) и соответствующее дерево решений (снизу)
Этот рекурсивный процесс строит в итоге бинарное дерево решений, в котором каждый узел соответствует определенному тесту. Кроме того, вы можете интерпретировать тест как разбиение части данных, рассматриваемое в данном случае вдоль одной оси. Это позволяет составить представление об алгоритме как способе выстроить иерархию разбиений. Поскольку каждый тест рассматривает только один признак, области, получающиеся в результате разбиения, всегда имеют границы, параллельные осям.
Рекурсивное разбиение данных повторяется до тех пор, пока все точки данных в каждой области разбиения (каждом листе дерева решений) не будут принадлежать одному и тому же значению целевой переменной (классу или количественному значению). Лист дерева, который содержит точки данных, относящиеся к одному и тому же значению целевой переменной, называется чистым (pure). Итоговое разбиение для нашего набора данных показано на рисунке 4.
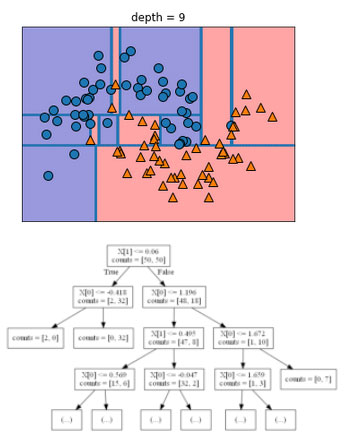
Рис.4. Граница принятия решений, полученная с помощью дерева глубиной 9 (сверху) и фрагмент соответствующего дерева (снизу), полное дерево имеет довольно большой размер и его сложно визуализировать
Прогноз для новой точки данных получают следующим образом: сначала выясняют, в какой области разбиения пространства признаков находится данная точка, а затем определяют класс, к которому относится большинство точек в этой области (либо единственный класс в области, если лист является чистым). Область может быть найдена с помощью обхода дерева, начиная с корневого узла и путем перемещения влево или вправо, в зависимости от того, выполняется ли тест или нет.
Кроме того, можно использовать деревья для решения задач регрессии, используя точно такой же подход. Для получения прогноза мы обходим дерево на основе тестов в каждом узле и находим лист, в который попадает новая точка данных. Выходом для этой точки данных будет значение целевой переменной, усредненное по всем обучающим точкам в этом листе.
На следующем шаге мы рассмотрим контроль сложности деревьев решений.
