На этом шаге мы рассмотрим организацию такого контроля.
Как правило, построение дерева, описанное здесь и продолжающееся до тех пор, пока все листья не станут чистыми, приводит к получению моделей, которые являются очень сложными и характеризуются сильным переобучением на обучающих данных. Наличие чистых листьев означает, что дерево имеет 100%-ную правильность на обучающей выборке. Каждая точка обучающего набора находится в листе, который имеет правильный мажоритарный класс. Переобучение можно увидеть в левой части рисунка 4 предыдущего шага.

Рис.2 (предыдущий шаг). Граница принятия решений, полученная с помощью дерева глубиной 1 (сверху) и соответствующее дерево решений (снизу)
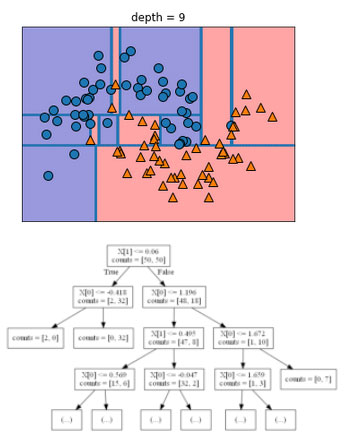
Рис.4 (предыдущий шаг). Граница принятия решений, полученная с помощью дерева глубиной 9 (сверху) и фрагмент соответствующего дерева (снизу), полное дерево имеет довольно большой размер и его сложно визуализировать
Видно, что точки, определяемые как точки класса 1, находятся посреди точек, принадлежащих к классу 0. С другой стороны, мы видим ряд точек, спрогнозированных как класс 1, вокруг точки, отнесенной к классу 0. Это не та граница принятия решений, которую мы могли бы себе представить. Здесь граница принятия решений фокусируется больше на отдельных точках-выбросах, которые находятся слишком далеко от остальных точек данного класса.
Есть две общераспространенные стратегии, позволяющие предотвратить переобучение.
- Первая стратегия - ранняя остановка построения дерева, называемая предварительной обрезкой (pre-pruning).
- Вторая стратегия - построение дерева с последующим удалением или сокращением малоинформативных узлов, называемое пост-обрезкой (post-pruning) или просто обрезкой (pruning).
В библиотеке scikit-learn деревья решений реализованы в классах DecisionTreeRegressor и DecisionTreeClassifier. Обратите внимание, в scikit-learn реализована лишь предварительная обрезка.
Давайте более детально посмотрим, как работает предварительная обрезка на примере набора данных Breast Cancer. Как всегда, мы импортируем набор данных и разбиваем его на обучающую и тестовую части. Затем мы строим модель, используя настройки по умолчанию для построения полного дерева (выращиваем дерево до тех пор, пока все листья не станут чистыми). Зафиксируем random_state для воспроизводимости результатов:
[In 3]: from sklearn.tree import DecisionTreeClassifier from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split cancer = load_breast_cancer() X_train, X_test, y_train, y_test = train_test_split( cancer.data, cancer.target, stratify=cancer.target, random_state=42) tree = DecisionTreeClassifier(random_state=0) tree.fit(X_train, y_train) print("Правильность на обучающем наборе: {:.3f}".format(tree.score(X_train, y_train))) print("Правильность на тестовом наборе: {:.3f}".format(tree.score(X_test, y_test))) Правильность на обучающем наборе: 1.000 Правильность на тестовом наборе: 0.937
Как и следовало ожидать, правильность на обучающем наборе составляет 100%, поскольку листья являются чистыми. Дерево имеет глубину, как раз достаточную для того, чтобы прекрасно запомнить все метки обучающих данных. Правильность на тестовом наборе немного хуже, чем при использовании ранее рассмотренных линейных моделей, правильность которых составляла около 95%.
Если не ограничить глубину, дерево может быть сколь угодно глубоким и сложным. Поэтому необрезанные деревья склонны к переобучению и плохо обобщают результат на новые данные. Теперь давайте применим к дереву предварительную обрезку, которая остановит процесс построения дерева до того, как мы идеально подгоним модель к обучающим данным. Один из вариантов - остановка процесса построения дерева по достижении определенной глубины. Здесь мы установим max_depth=4, то есть можно задать только четыре последовательных вопроса (см. рисунки 2 и 4 предыдущего шага). Ограничение глубины дерева уменьшает переобучение. Это приводит к более низкой правильности на обучающем наборе, но улучшает правильность на тестовом наборе:
[In 4]: tree = DecisionTreeClassifier(max_depth=4, random_state=0) tree.fit(X_train, y_train) print("Правильность на обучающем наборе: {:.3f}".format(tree.score(X_train, y_train))) print("Правильность на тестовом наборе: {:.3f}".format(tree.score(X_test, y_test))) Правильность на обучающем наборе: 0.988 Правильность на тестовом наборе: 0.951
На следующем шаге мы рассмотрим анализ деревьев решений.
