На этом шаге мы рассмотрим использование деревьев в регресии.
Несмотря на то что мы сосредоточились на прошлом шаге на деревьях классификации, все вышесказанное верно и для деревьев регрессии, которые реализованы в DecisionTreeRegressor. Применение и анализ деревьев регрессии очень схожи с применением и анализом деревьев классификации. Однако существует одна особенность использования деревьев регрессии, на которую нужно указать. DecisionTreeRegressor (и все остальные регрессионные модели на основе дерева) не умеет экстраполировать или делать прогнозы вне диапазона значений обучающих данных.
Давайте детальнее рассмотрим это, воспользовавшись набором данных RAM Price (содержит исторические данные о ценах на компьютерную память). Рисунок 1 визуализирует этот набор данных, дата отложена по оси х, а цена одного мегабайта оперативной памяти в соответствующем году - по оси у:
[In 14]: import pandas as pd ram_prices = pd.read_csv("C:/Temp/Data/ram_price.csv") plt.semilogy(ram_prices.date, ram_prices.price) plt.xlabel("Год") plt.ylabel("Цена $/Мбайт")
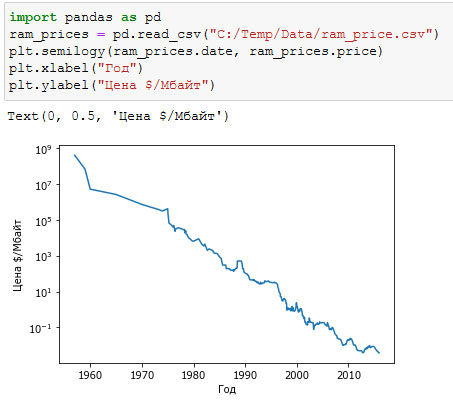
Рис.1. Историческое развитие цен на RAM по логарифмической шкале
 Скачайте набор данных ram_price.csv по ссылке и поместите его в папку Temp/Data на диске C.
Скачайте набор данных ram_price.csv по ссылке и поместите его в папку Temp/Data на диске C.
Обратите внимание на логарифмическую шкалу оси у. При логарифмическом преобразовании взаимосвязь выглядит вполне линеиной и таким образом становится легко прогнозируемой, за исключением некоторых всплесков.
Мы будем прогнозировать цены на период после 2000 года, используя исторические данные до этого момента, единственным признаком будут даты. Мы сравним две простые модели: DecisionTreeRegressor и LinearRegression. Мы отмасштабируем цены, используя логарифм, таким образом, взаимосвязь будет относительно линейной. Это несущественно для DecisionTreeRegressor, однако существенно для LinearRegression (мы рассмотрм ее более подробно позже). После обучения модели и получения прогнозов мы применим экспоненцирование, чтобы обратить логарифмическое преобразование. Мы получим и визуализируем прогнозы для всего набора данных, но для количественной оценки мы будем рассматривать только тестовый набор:
[In 15]: from sklearn.tree import DecisionTreeRegressor from sklearn import linear_model # используем исторические данные для прогнозирования цен после 2000 года data_train = ram_prices[ram_prices.date < 2000] data_test = ram_prices[ram_prices.date >= 2000] # прогнозируем цены по датам X_train = data_train.date[:, np.newaxis] # мы используем логпреобразование, что получить простую взаимосвязь # между данными и откликом y_train = np.log(data_train.price) tree = DecisionTreeRegressor().fit(X_train, y_train) linear_reg = linear_model.LinearRegression().fit(X_train, y_train) # прогнозируем по всем данным X_all = ram_prices.date[:, np.newaxis] pred_tree = tree.predict(X_all) pred_lr = linear_reg.predict(X_all) # экспоненцируем, чтобы обратить логарифмическое преобразование price_tree = np.exp(pred_tree) price_lr = np.exp(pred_lr)
Рисунок 2, созданный здесь, сравнивает прогнозы дерева решений и линейной регрессии с реальными.
[In 16]: plt.semilogy(data_train.date, data_train.price, label="Обучающие данные") plt.semilogy(data_test.date, data_test.price, label="Тестовые данные") plt.semilogy(ram_prices.date, price_tree, label="Прогнозы дерева") plt.semilogy(ram_prices.date, price_lr, label="Прогнозы линейной регрессии") plt.legend()
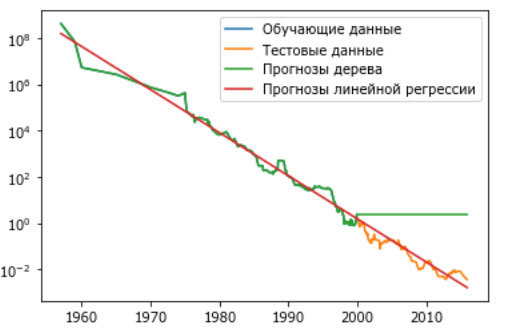
Рис.2. Сравнение прогнозов линейной модели и прогнозов дерева регрессии для набора данных RAM price
Разница между моделями получилась весьма впечатляющая. Линейная модель аппроксимирует данные с помощью уже известной нам прямой линии. Эта линия дает достаточно хороший прогноз для тестовых данных (период после 2000 года), при этом сглаживая некоторые всплески в обучающих и тестовых данных. С другой стороны, модель дерева прекрасно прогнозирует на обучающих данных. Здесь мы не ограничивали сложность дерева, поэтому она полностью запомнила весь набор данных. Однако, как только мы выходим из диапазона значений, известных модели, модель просто продолжает предсказывать последнюю известную точку. Дерево не способно генерировать "новые" ответы, выходящие за пределы значений обучающих данных. Этот недостаток относится ко всем моделям на основе деревьев решений.
Архив блокнота со всеми вычислениями, выполненными на шагах 47-52, можно взять здесь.
На самом деле с помощью деревьев решений можно получать очень точные прогнозы (например, предсказать, будет ли цена повышаться или понижаться). Суть этого примера была не в том, чтобы
показать, что деревья являются плохой моделью для временных рядов, а в том, чтобы конкретно показать, как деревья делают прогнозы.
На следующем шаге мы рассмотрим преимущества, недостатки и параметры.
