На этом шаге мы рассмотрим, что из себя представляет прямое кодирование.
На сегодняшний момент наиболее распространенным способом представления категориальных переменных является прямое кодирование или, если перевести дословно, кодирование с одним горячим состоянием (one-hot-encoding или one-out-of-N encoding). Идея, лежащая в основе прямого кодирования, заключается в том, чтобы заменить категориальную переменную одной или несколькими новыми признаками, которые могут принимать значения 0 и 1. Значения 0 и 1 придают смысл формуле линейной бинарной классификации (а также всем остальным моделям в scikit-learn) и с помощью дамми-переменных мы можем выразить любое количество категорий, вводя по одному новому признаку для каждой категории.
Скажем, признак workclass имеет возможные значения "Government Employee", "Private Employee", "Self Employed" и "Self Employed Incorporated". Для того, чтобы закодировать эти четыре возможных значения, мы создаем четыре новых характеристики "Government Employee", "Private Employee", "Self Employed" и "Self Employed Incorporated". Характеристика равна 1, если workclass принимает соответствующее значение, или равна 0 в противном случае, поэтому для каждой точки данных только одна из четырех новых характеристик будет равна 1. Вот почему данная операция называется кодированием с одним горячим (активным) состоянием.
Этот принцип показан в таблице 1. Один признак кодируется с помощью четырех новых характеристик. Включив эту информацию в модель машинного обучения, мы не используем исходный признак workclass, а работаем только с этими четырьмя характеристиками 0-1.
| workclass | Government Employee | Private Employee | Self Employed | Self Employed Incorporated |
|---|---|---|---|---|
| Government Employee | 1 | 0 | 0 | 0 |
| Private Employee | 0 | 1 | 0 | 0 |
| Self Employed | 0 | 0 | 1 | 0 |
| Self Employed Incorporated | 0 | 0 | 0 | 1 |
 Прямое кодирование, которое мы используем, довольно схоже с дамми-кодированием, применяемым в статистике, но не идентично ему. В целях упрощения мы кодируем категории переменной с
помощью бинарных признаков. В статистике категориальную переменную, принимающую k различных возможных значений (категорий), обшепринято кодировать с помощью k-1
признаков, при этом для последней категории все признаки будут иметь нулевые значения. Это делается для упрощения анализа (говоря более техническим языком, это позволяет избежать
получения матрицы неполного ранга).
Прямое кодирование, которое мы используем, довольно схоже с дамми-кодированием, применяемым в статистике, но не идентично ему. В целях упрощения мы кодируем категории переменной с
помощью бинарных признаков. В статистике категориальную переменную, принимающую k различных возможных значений (категорий), обшепринято кодировать с помощью k-1
признаков, при этом для последней категории все признаки будут иметь нулевые значения. Это делается для упрощения анализа (говоря более техническим языком, это позволяет избежать
получения матрицы неполного ранга).
Существует два способа выполнить прямое кодирование категориальных переменных, используя либо pandas, либо scikit-learn. И использование pandas нам представляется немного проще, поэтому давайте поидем по этому пути. Сначала с помощью pandas загрузим данные, записанные в CSV-файле:
[In 2]: import pandas as pd # Файл не содержит заголовков столбцов, поэтому мы передаем header=None # и записываем имена столбцов прямо в "names" data = pd.read_csv("D:/adult.data", header=None, index_col=False, names=['age', 'workclass', 'fnlwgt', 'education', 'education-num', 'marital-status', 'occupation', 'relationship', 'race', 'gender', 'capital-gain', 'capital-loss', 'hours-per-week', 'native-country', 'income']) # В целях упрощения мы выберем лишь некоторые столбцы data = data[['age', 'workclass', 'education', 'gender', 'hours-per-week', 'occupation', 'income']] # IPython.display позволяет вывести красивый вывод, отформатированный в Jupyter notebook display(data.head())
На рисунке 1 показан результат.
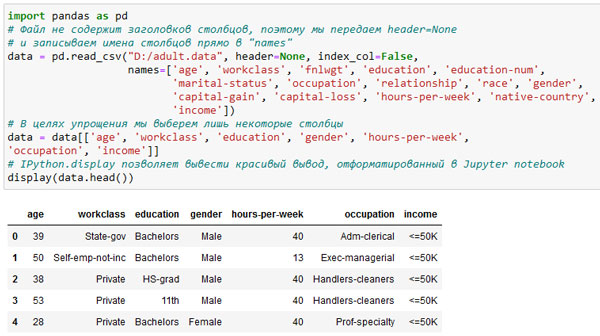
Рис.1. Первые пять строк набора данных adult
На следующем шаге мы рассмотрим проверку категориальных данных, закодированных в виде строк.
