На этом шаге мы рассмотрим использование таких признаков.
С помощью одномерных статистик мы определяем наличие статистически значимой взаимосвязи между каждым признаком и зависимой переменной. Затем отбираем признаки, сильнее всего связанные с зависимой переменной (имеющие уровень значимости, не превышающий заданного порогового значения). В случае классификации эта процедура известна как дисперсионный анализ (ANOVA). Ключевым свойством этих тестов является то, что они являются одномерными, то есть они рассматривают каждую характеристику по отдельности. Следовательно признак будет исключен, если он становится информативным лишь в сочетании с другим признаком. Как правило, одномерные тесты очень быстро вычисляются и не требуют построения модели. С другой стороны, они являются полностью независимыми от модели, которой вы, возможно, захотите применить после отбора признаков.
Чтобы осуществить одномерный отбор признаков в scikit-learn, вам нужно выбрать тест, обычно либо f_classif (по умолчанию) для классификации или f_regression для регрессии, а также метод исключения признаков, основанный на p-значениях, вычисленных в ходе теста. Все методы исключения параметров используют пороговое значение, чтобы исключить все признаки со слишком высоким р-значением (высокое p-значение указывает на то, что признак вряд ли связан с зависимой переменной). Методы отличаются способами вычисления этого порогового значения, самым простым из которых являются SelectKB, выбирающий фиксированное число k признаков, и SelectPercentile, выбирающий фиксированный процент признаков. Давайте применим отбор признаков для классификационной задачи к набору данных cancer. Чтобы немного усложнить задачу, мы добавим к данным некоторые неинформативные шумовые признаки. Мы предполагаем, что отбор признаков сможет определить неинформативные признаки и удалит их:
[In 39]: from sklearn.datasets import load_breast_cancer from sklearn.feature_selection import SelectPercentile from sklearn.model_selection import train_test_split cancer = load_breast_cancer() # задаем определенное стартовое значение для воспроизводимости результата rng = np.random.RandomState(42) noise = rng.normal(size=(len(cancer.data), 50)) # добавляем к данным шумовые признаки # первые 30 признаков являются исходными, остальные 50 являются шумовыми X_w_noise = np.hstack([cancer.data, noise]) X_train, X_test, y_train, y_test = train_test_split( X_w_noise, cancer.target, random_state=0, test_size=.5) # используем f_classif (по умолчанию) # и SelectPercentile, чтобы выбрать 50% признаков select = SelectPercentile(percentile=50) select.fit(X_train, y_train) # преобразовываем обучающий набор X_train_selected = select.transform(X_train) print("форма массива X_train: {}".format(X_train.shape)) print("форма массива X_train_selected: {}".format(X_train_selected.shape)) форма массива X_train: (284, 80) форма массива X_train_selected: (284, 40)
Как видно, количество признаков уменьшилось с 80 до 40 (на 50% от исходного количества признаков). Мы можем выяснить, какие функции были отобраны, воспользовавшись методом get_support(), который возвращает булевы значения для каждого признака (визуализированы на рисунке 1):
[In 40]: mask = select.get_support() print(mask) # визуализируем булевы значения: черный – True, белый – False plt.matshow(mask.reshape(1, -1), cmap='gray_r') plt.xlabel("Индекс примера")
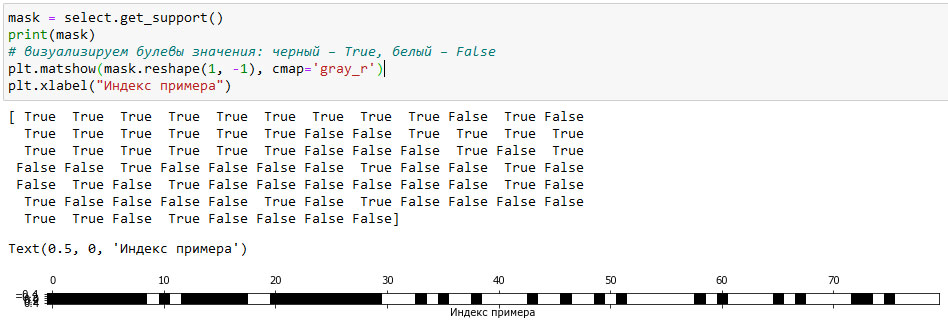
Рис.1. Признаки, отобранные с помощью SelectPercentile() (изображение кликабельно)
Благодаря визуализации видно, что большинство отобранных признаков являются исходными характеристиками, а большинство шумовых признаков были удалены. Тем не менее восстановление исходных признаков далеко от идеала. Давайте сравним правильность логистической регрессии с использованием всех признаков с правильностью логистическом регрессии, использующем лишь отобранные признаки:
[In 41]: from sklearn.linear_model import LogisticRegression # преобразовываем тестовые данные X_test_selected = select.transform(X_test) lr = LogisticRegression(max_iter=600) lr.fit(X_train, y_train) print("Правильность со всеми признаками: {:.3f}".format(lr.score(X_test, y_test))) lr.fit(X_train_selected, y_train) print("Правильность только с отобранными признаками: {:.3f}".format( lr.score(X_test_selected, y_test))) Правильность со всеми признаками: 0.926 Правильность только с отобранными признаками: 0.940
В данном случае удаление шумовых признаков повысило правильность, даже несмотря на то, что некоторые исходные признаки отсутствовали. Кстати, при изменении количества итераций (параметр max_iter), полученное соотношение может меняться (проверьте!).
Это был очень простой синтетический пример, результаты, получающиеся на реальных данных, как правило, получаются смешанными. Однако одномерный отбор признаков может быть очень полезен, если их количество является настолько большим, что невозможно построить модель, используя все эти характеристики, или же вы подозреваете, что многие характеристики совершенно неинформативны.
На следующем шаге мы рассмотрим отбор признаков на основе модели.
