На этом шаге мы рассмотрим стратифицированную k-блочную перекрестную проверку.
Описанное в предыдущем шаге разбиение данных на k блоков, начиная с первого k-го блока, не всегда является хорошей идеей. Для примера давайте посмотрим на набор данных iris:
[In 6]: from sklearn.datasets import load_iris iris = load_iris() print("Метки ирисов:\n{}".format(iris.target)) Метки ирисов: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
Как видно, первая треть данных - это класс 0, вторая треть - класс 1, а последняя треть - класс 2. Представьте, что сделает с этим набором данных трехблочная перекрестная проверка. Первый блок будет состоять из примеров, относящихся только к классу 0, поэтому при первом разбиении данных тестовый набор станет полностью классом 0, а обучающий набор будет содержать примеры, относящиеся только к классам 1 и 2. Поскольку классы в обучающем и тестовом наборах будут разными во всех трех разбиениях, правильность трехблочной перекрестной проверки для этого набора данных будет равна нулю. Данный сценарий не является оптимальным, поскольку для набора данных iris мы можем получить правильность существенно выше 0%.
Поскольку обычная k-блочная стратегия в данном случае терпит неудачу, вместо нее библиотека scikit-learn предлагает использовать для классификации стратифицированную k-блочную перекрестную проверку (stratified k-fold cross-validation). В стратифицированной перекрестной проверке мы разбиваем данные таким образом, чтобы пропорции классов в каждом блоке в точности соответствовали пропорциям классов в наборе данных, как это показано на рисунке 1:
[In 7]:
mglearn.plots.plot_stratified_cross_validation()
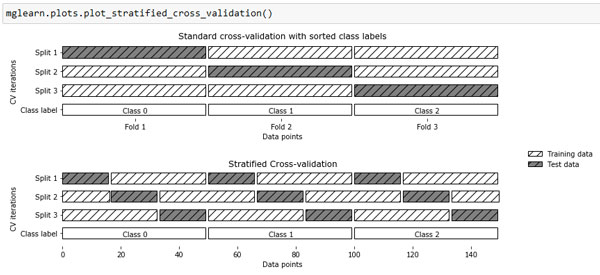
Рис.1. Сравнение стандартной перекрестной проверки и стратифицированной перекрестной проверки, когда данные упорядочены по меткам классов
Например, если 90% примеров относятся к классу А, а 10% примеров - к классу В, то стратифицированная перекрестная проверка выполняется так, чтобы в каждом блоке 90% примеров принадлежали к классу А, а 10% примеров - к классу B.
Использование для оценки классификатора стратифицированной k-блочной перекрестной проверки вместо обычной k-блочной перекрестной является хорошей идеей, поскольку позволяет получить более надежные оценки обобщающей способности. В ситуации, когда лишь 10% примеров принадлежат к классу В, использование стандартной k-блочной перекрестной проверки может привести к тому, что один из блоков будет полностью состоять из примеров, относящихся к классу А. Использование этого блока в качестве тестового набора не даст особой информации о качестве работы классификатора.
Для регрессии в scikit-learn по умолчанию используется стандартная k-блочная кросс-проверка. Можно было бы еще попытаться создать блоки, представляющие различные значения количественной зависимой переменной, но данный метод не является общераспространенной стратегией и был бы неожиданностью для большинства пользователей.
На следующем шаге мы продолжим изучение этого вопроса.
