На этом шаге мы рассмотрим особенности организации такого поиска.
Хотя только что рассмотренный нами метод разбиения данных на обучающий, проверочный и тестовый наборы является вполне рабочим и относительно широко используемым, он весьма чувствителен к правильности разбиения данных. Взглянув на вывод, приведенный для программного кода фрагмента из предыдущего шага, мы видим, что GridSearchCV выбрал в качестве лучших параметров 'C': 10, 'gamma': 0.001, тогда как вывод, приведенный для программного кода из 142 шага, сообщает нам, что наилучшими параметрами являются 'C': 100, 'gamma': 0.001. Для лучшей оценки обобщающей способности вместо одного разбиения данных на обучающий и проверочный наборы мы можем воспользоваться перекрестной проверкой. Теперь качество модели оценивается для каждой комбинации параметров по всем разбиениям перекрестной проверки. Этот метод можно реализовать с помощью следующего программного кода:
[In 20]: for gamma in [0.001, 0.001, 0.1, 1, 10, 100]: for C in [0.001, 0.001, 0.1, 1, 10, 100]: # для каждой комбинации параметров, # обучаем SVC svm = SVC(gamma=gamma, C=C) # выполняем перекрестную проверку scores = cross_val_score(svm, X_trainval, y_trainval, cv=5) # вычисляем среднюю правильность перекрестной проверки score = np.mean(scores) # если получаем лучшее значение правильности, сохраняем значение и параметры if score > best_score: best_score = score best_parameters = {'C': C, 'gamma': gamma} # заново строим модель на наборе, полученном в результате # объединения обучающих и проверочных данных svm = SVC(**best_parameters) svm.fit(X_trainval, y_trainval) SVC(C=10, gamma=0.1)
Чтобы c помощью пятиблочной перекрестной проверки оценить правильность SVM для конкретной комбинации значений C и gamma, нам необходимо обучить 36*5=180 моделей. Как вы понимаете, основным недостатком использования перекрестной проверки является время, которое требуется для обучения всех этих моделей.
Следующая визуализация (рисунок 1) показывает, как в предыдущем программном коде осуществляется выбор оптимальных параметров:
[In 21]:
mglearn.plots.plot_cross_val_selection()
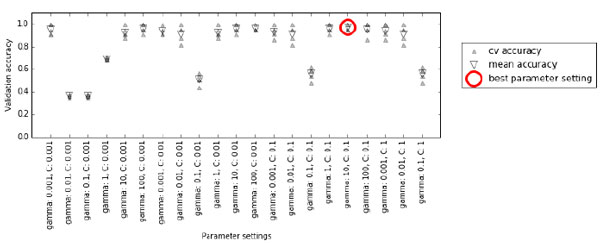
Рис.1. Результаты решетчатого поиска с перекрестной проверкой
Для каждой комбинации значений С и gamma (здесь показана лишь часть комбинаций) вычисляются пять значений правильности, по одному для каждого разбиения в перекрестной проверке. Затем для каждой комбинации параметров вычисляется среднее значение правильности перекрестной проверки. В итоге выбирается комбинация с наибольшей средней правильностью перекрестной проверки и отмечается кружком.
 Как мы уже говорили ранее, перекрестная проверка - это способ оценить качество работы конкретного алгоритма на определенном наборе данных. Однако она часто используется в сочетании с методами
поиска параметров типа решетчатного поиска. По этой причине многие люди в разговорной речи под термином перекрестная проверка (cross-validation) подразумевают
решетчатый поиск с перекрестной проверкой.
Как мы уже говорили ранее, перекрестная проверка - это способ оценить качество работы конкретного алгоритма на определенном наборе данных. Однако она часто используется в сочетании с методами
поиска параметров типа решетчатного поиска. По этой причине многие люди в разговорной речи под термином перекрестная проверка (cross-validation) подразумевают
решетчатый поиск с перекрестной проверкой.
Общий процесс разбиения данных, запуска решетчатого поиска, а также оценки итоговых параметров показан на рисунке 2:
[In 22]:
mglearn.plots.plot_grid_search_overview()
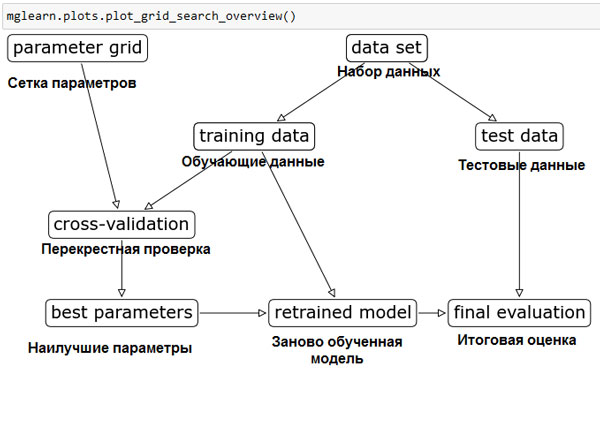
Рис.2. Процесс отбора параметров и оценки модели с помощью GridSearchCV
На следующем шаге мы закончим изучение этого вопроса.
