На этом шаге мы рассмотрим различные алгоритмы реализации параллельных вычислений.
Умножение матриц при блочной схеме разделения данных
При блочной схеме разбиения матриц исходные матрицы А, В и результирующая матрица С представляются в виде наборов блоков. Будем предполагать далее, что все матрицы являются квадратными размера n*n, количество блоков по горизонтали и вертикали являются одинаковым и равным q (т.е. размер всех блоков равен k*k, k=n/q). При таком представлении данных операция матричного умножения матриц А и B в блочном виде может быть представлена в виде:
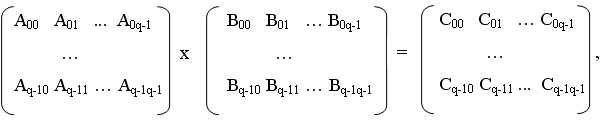
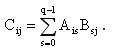
При блочном разбиении данных для определения базовых подзадач естественным представляется взять за основу вычисления, выполняемые над матричными блоками. С учетом сказанного определим базовую подзадачу как процедуру вычисления всех элементов одного из блоков матрицы С.
Вычисления должны быть организованы таким образом, чтобы в каждый текущий момент времени подзадачи содержали лишь часть необходимых для проведения расчетов данных, а доступ к остальной части данных обеспечивался бы при помощи передачи сообщений. Рассмотрим два возможных подхода к решению этой проблемы - алгоритм Фокса и алгоритм Кэннона.
Алгоритм Фокса умножения матриц. Выделение информационных зависимостей
Для нумерации подзадач будем использовать индексы размещаемых в подзадачах блоков матрицы C, т.е. подзадача (i,j) отвечает за вычисление блока Cij - тем самым, набор подзадач образует квадратную решетку, соответствующую структуре блочного представления матрицы C.
В соответствии с алгоритмом Фокса в ходе вычислений на каждой базовой подзадаче (i,j) располагается четыре матричных блока:
- блок Cij матрицы C, вычисляемый подзадачей;
- блок Aij матрицы A, размещаемый в подзадаче перед началом вычислений;
- блоки A'ij, B'ij матриц A и B, получаемые подзадачей в ходе выполнения вычислений.
Выполнение параллельного метода включает:
- Этап инициализации, на котором каждой подзадаче (i,j) передаются блоки Aij, Bij и обнуляются блоки Cij на всех подзадачах.
- Этап вычислений, в рамках которого на каждой итерации l, 0<=l<q, осуществляются следующие операции:
- для каждой строки i, 0<=i<q, блок Aij подзадачи (i,j) пересылается на все подзадачи той же строки i решетки; индекс j, определяющий положение подзадачи в строке, вычисляется в соответствии с выражением j = ( i+l ) mod q, где mod есть операция получения остатка от целочисленного деления;
- полученные в результаты пересылок блоки A'ij, B'ij каждой подзадачи (i,j) перемножаются и прибавляются к блоку Cij: Cij= Cij+ A'ij*B'ij;
- блоки B'ij каждой подзадачи (i,j) пересылаются подзадачам, являющимися соседями сверху в столбцах решетки подзадач (блоки подзадач из первой строки решетки пересылаются подзадачам последней строки решетки).
Алгоритм Кэннона умножения матриц
Как и при рассмотрении алгоритма Фокса, в качестве базовой подзадачи выберем вычисления, связанные с определением одного из блоков результирующей матрицы C.
Выделение информационных зависимостей
Отличие алгоритма Кэннона от метода Фокса состоит в изменении схемы начального распределения блоков перемножаемых матриц между подзадачами вычислительной системы. Начальное расположение блоков в алгоритме Кэннона подбирается таким образом, чтобы располагаемые блоки в подзадачах могли бы быть перемножены без каких-либо дополнительных передач данных. При этом подобное распределение блоков может быть организовано таким образом, что перемещение блоков между подзадачами в ходе вычислений может осуществляться с использованием более простых коммуникационных операций.
С учетом высказанных замечаний этап инициализации алгоритма Кэннона включает выполнение следующих операций передач данных:
- В каждую подзадачу (i,j) передаются блоки Aij, Bij.
- Для каждой строки i решетки подзадач блоки матрицы A сдвигаются на (i-1) позиций влево.
- Для каждого столбца j решетки подзадач блоки матрицы B сдвигаются на (j-1) позиций вверх.
Выполняемые при перераспределении матричных блоков процедуры передачи данных являются примером операции циклического сдвига. В результате такого начального распределения в каждой базовой подзадаче будут располагаться блоки, которые могут быть перемножены без дополнительных операций передачи данных. Кроме того, получение всех последующих блоков для подзадач может быть обеспечено при помощи простых коммуникационных действий - после выполнения операции блочного умножения каждый блок матрицы A должен быть передан предшествующей подзадаче влево по строкам решетки подзадач, а каждый блок матрицы В - предшествующей подзадаче вверх по столбцам решетки. Последовательность таких циклических сдвигов и умножение получаемых блоков исходных матриц A и B приведет к получению в базовых подзадачах соответствующих блоков результирующей матрицы C.
Масштабирование и распределение подзадач по процессорам
Для алгоритма Кэннона размер блоков может быть подобран таким образом, чтобы количество базовых подзадач совпадало с числом имеющихся процессоров. Поскольку объем вычислений в каждой подзадаче является равным, это обеспечивает полную балансировку вычислительной нагрузки между процессорами.
Для распределения подзадач между процессорами может быть применен подход, использованный в алгоритме Фокса - множество имеющихся процессоров представляется в виде квадратной решетки и размещение базовых подзадач (i,j) осуществляется на процессорах Pij соответствующих узлов процессорной решетки. Необходимая структура сети передачи данных может быть обеспечена на физическом уровне при топологии вычислительной системы в виде решетки или полного графа.
Анализ эффективности алгоритма Фокса
Будем считать, что все матрицы являются квадратными размера n*n, количество блоков по горизонтали и вертикали являются одинаковым и равным q (т.е. размер всех блоков равен k*k, k=n/q), процессоры образуют квадратную решетку и их количество равно p=q2.
Алгоритм Фокса требует для своего выполнения q итераций, в ходе которых каждый процессор перемножает свои текущие блоки матриц А и В и прибавляет результаты умножения к текущему значению блока матрицы C. С учетом выдвинутых предположений общее количество выполняемых при этом операций будет иметь порядок n3/p. Как результат, показатели ускорения и эффективности алгоритма имеют вид:
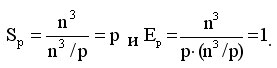
Уточним полученные соотношения - укажем для этого более точно количество вычислительных операций алгоритма и учтем затраты на выполнение операций передачи данных между процессорами.
Определим количество вычислительных операций. Сложность выполнения скалярного умножения строки блока матрицы A на столбец блока матрицы В можно оценить как 2(n/q) - 1. Количество строк и столбцов в блоках равно n/q и, как результат, трудоемкость операции блочного умножения оказывается равной (n2/p)(2n/q - 1). Для сложения блоков требуется n2/p операций. С учетом всех перечисленных выражений время выполнения вычислительных операций алгоритма Фокса может быть оценено следующим образом:
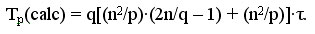
Оценим затраты на выполнение операций передачи данных между процессорами. На каждой итерации алгоритма перед умножением блоков один из процессоров строки процессорной решетки рассылает свой блок матрицы A остальным процессорам своей строки. При топологии сети в виде гиперкуба или полного графа выполнение этой операции может быть обеспечено за log2q шагов, а объем передаваемых блоков равен n2/p. Как результат, время выполнения операции передачи блоков матрицы A при использовании модели Хокни может оцениваться как
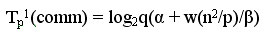
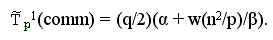
Далее после умножения матричных блоков процессоры передают свои блоки матрицы В предыдущим процессорам по столбцам процессорной решетки (первые процессоры столбцов передают свои данные последним процессорам в столбцах решетки). Эти операции могут быть выполнены процессорами параллельно и, тем самым, длительность такой коммуникационной операции составляет:
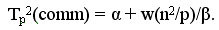
Просуммировав все полученные выражения, можно получить, что общее время выполнения алгоритма Фокса может быть определено при помощи следующих соотношений:
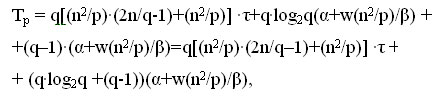
На следующем шаге мы закончим изучение этого вопроса.
