На этом шаге мы рассмотрим суть этой операции и особенности ее реализации.
Выделение признаков заключается в использовании представлений, изученных предварительно обученной моделью, для выделения признаков из новых образцов. Эти признаки затем пропускаются через новый классификатор, обучаемый с нуля.
Как было показано выше, сверточные нейронные сети, используемые для классификации изображений, состоят из двух частей: они начинаются с последовательности слоев выбора значений и свертки и заканчиваются полносвязным классификатором. Первая часть называется сверточной основой (convolutional base) модели. В случае со сверточными нейронными сетями процесс выделения признаков заключается в том, чтобы взять сверточную основу предварительно обученной сети, пропустить через нее новые данные и на основе вывода обучить новый классификатор (рисунок 1).
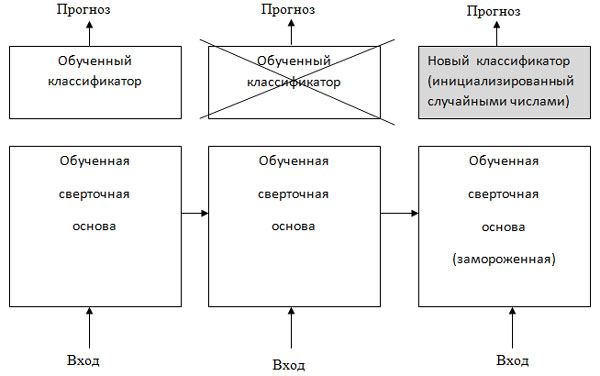
Рис.1. Замена классификаторов при использовании одной и той же сверточной основы
Почему повторно используется только сверточная основа? Нельзя ли снова взять полносвязный классификатор? В общем случае этого следует избегать. Причина в том, что представления, полученные сверточной основой, обычно более универсальны, а значит, более пригодны для повторного использования: карты признаков сверточной нейронной сети - это карты присутствия на изображениях обобщенных понятий, которые могут пригодиться независимо от конкретной задачи распознавания образов. Но представления, изученные классификатором, обязательно будут характерны для набора классов, на котором обучалась модель: они будут содержать только информацию о вероятности присутствия того или иного класса на изображении. Кроме того, представления, присутствующие в полносвязных слоях, не содержат никакой информации о местоположении объекта на исходном изображении (эти слои лишены понятия пространства), тогда как сверточные карты признаков все еще хранят ее. Для задач, где местоположение объектов имеет значение, полносвязные признаки почти бесполезны.
Отметим также, что уровень обобщенности (и, соответственно, пригодности к повторному использованию) представлений, выделенных конкретными сверточными слоями, зависит от глубины слоя в модели. Слои, следующие первыми, выделяют локальные, наиболее обобщенные карты признаков (таких как визуальные границы, цвет и текстура), тогда как слои, располагающиеся дальше (или выше), выделяют более абстрактные понятия (такие как "глаз кошки" или "глаз собаки"). Поэтому, если новый набор данных существенно отличается от набора, на котором обучалась оригинальная модель, возможно, большего успеха получится добиться, если использовать только несколько первых слоев модели, а не всю сверточную основу.
В нашем случае, поскольку набор классов ImageNet содержит несколько классов кошек и собак, вероятно, было бы полезно снова использовать информацию, содержащуюся в полносвязных слоях оригинальной модели. Но мы не будем этого делать, чтобы охватить более общий случай, когда набор классов из новой задачи не пересекается с набором классов оригинальной модели. Давайте перейдем к практике и используем сверточную основу сети VGG16, обученной на данных ImageNet, для выделения полезных признаков из изображений кошек и собак, а затем обучим классификатор кошек и собак, опираясь на эти признаки.
Модель VGG16 входит в состав Keras. Ее можно импортировать из модуля keras.applications. Вот список моделей классификации изображений (все они предварительно обучены на наборе ImageNet), доступных в keras.applications:
- Xception;
- ResNet;
- MobileNet;
- EfficientNet;
- DenseNet и др.
Создадим экземпляр модели VGG16.
Пример 8.19. Создание экземпляра сверточной основы VGG16
conv_base = keras.applications.vgg16.VGG16(
weights="imagenet",
include_top=False,
input_shape=(180, 180, 3))
Здесь конструктору передаются три аргумента:
- аргумент weights определяет источник весов для инициализации модели;
- аргумент include_top определяет необходимость подключения к сети полносвязного классификатора. По умолчанию полносвязный классификатор определяет принадлежность изображения к 1000 классов.
Так как мы намереваемся использовать свой полносвязный классификатор (только с двумя классами, cat и dog), мы не будем подключать его;
- аргумент input_shape определяет форму тензоров с изображениями, которые будут подаваться на вход сети. Это необязательный аргумент: если опустить
его, сеть сможет обрабатывать изображения любого размера. В нашем примере мы передаем его, чтобы иметь возможность видеть (в следующей сводке), как
уменьшается размер карт признаков с каждым новым слоем свертки и объединения.
Далее приводится информация о сверточной основе VGG16. Она напоминает простые сверточные нейронные сети, уже знакомые вам:
conv_base.summary() Model: "vgg16" Layer (type) Output Shape Param # input_layer (InputLayer) (None, 180, 180, 3) 0 block1_conv1 (Conv2D) (None, 180, 180, 64) 1,792 block1_conv2 (Conv2D) (None, 180, 180, 64) 36,928 block1_pool (MaxPooling2D) (None, 90, 90, 64) 0 block2_conv1 (Conv2D) (None, 90, 90, 128) 73,856 block2_conv2 (Conv2D) (None, 90, 90, 128) 147,584 block2_pool (MaxPooling2D) (None, 45, 45, 128) 0 block3_conv1 (Conv2D) (None, 45, 45, 256) 295,168 block3_conv2 (Conv2D) (None, 45, 45, 256) 590,080 block3_conv3 (Conv2D) (None, 45, 45, 256) 590,080 block3_pool (MaxPooling2D) (None, 22, 22, 256) 0 block4_conv1 (Conv2D) (None, 22, 22, 512) 1,180,160 block4_conv2 (Conv2D) (None, 22, 22, 512) 2,359,808 block4_conv3 (Conv2D) (None, 22, 22, 512) 2,359,808 block4_pool (MaxPooling2D) (None, 11, 11, 512) 0 block5_conv1 (Conv2D) (None, 11, 11, 512) 2,359,808 block5_conv2 (Conv2D) (None, 11, 11, 512) 2,359,808 block5_conv3 (Conv2D) (None, 11, 11, 512) 2,359,808 block5_pool (MaxPooling2D) (None, 5, 5, 512) 0 Total params: 14,714,688 (56.13 MB) Trainable params: 14,714,688 (56.13 MB) Non-trainable params: 0 (0.00 B)
Заключительная карта признаков имеет форму (5, 5, 512). Поверх нее мы положим полносвязный классификатор.
Далее можно пойти двумя путями:
- пропустить наш набор данных через сверточную основу, записать получившийся массив NumPy на диск и затем использовать его как входные
данные для отдельного полносвязного классификатора. Это быстрое и незатратное решение, потому что требует запускать сверточную основу только один раз
для каждого входного изображения, а сверточная основа - самая дорогостоящая часть конвейера. Однако по той же причине этот прием не позволит
использовать прием обогащения данных;
- дополнить имеющуюся модель (conv_base) слоями Dense и пропустить все входные данные. Этот путь позволяет использовать обогащение
данных, потому что каждое изображение проходит через сверточную основу каждый раз, когда попадает в модель. Однако по той же причине этот путь намного
более затратный, чем первый.
Мы охватим оба приема. Сначала рассмотрим код, реализующий первый прием: запись вывода conv_base в ответ на передачу наших данных и его использование в роли входных данных новой модели.
На следующем шаге мы рассмотрим быстрое выделение признаков без обогащения данных.
