На этом шаге мы рассмотрим реализацию этого приема.
Сначала выделим признаки в массив NumPy, вызвав метод predict() модели conv_base для обучающих, проверочных и контрольных данных.
Для этого выполним обход наших наборов данных и выделим признаки VGG16.
Пример 8.20. Выделение признаков VGG16 и соответствующих меток
import numpy as np def get_features_and_labels(dataset): all_features = [] all_labels = [] for images, labels in dataset: preprocessed_images = keras.applications.vgg16.preprocess_input(images) features = conv_base.predict(preprocessed_images) all_features.append(features) all_labels.append(labels) return np.concatenate(all_features), np.concatenate(all_labels) train_features, train_labels = get_features_and_labels(train_dataset) val_features, val_labels = get_features_and_labels(validation_dataset) test_features, test_labels = get_features_and_labels(test_dataset)
Важно отметить, что predict() принимает только изображения, без меток, а наш объект набора данных выдает пакеты, содержащие как изображения, так и их метки. Более того, модель VGG16 принимает данные, предварительно обработанные с помощью функции keras.applications.vgg16.preprocess_input(), которая приводит значения пикселей в соответствующий диапазон.
В настоящий момент выделенные признаки имеют форму (образцы, 5, 5, 512):
print(train_features.shape)
(2000, 5, 5, 512)
Теперь можно определить полносвязный классификатор (обратите внимание, что для регуляризации здесь используется прием прореживания) и обучить его на только что записанных данных и метках.
Пример 8.21. Определение и обучение полносвязного классификатора i
nputs = keras.Input(shape=(5, 5, 512)) # Обратите внимание, что перед передачей признаков в слой # Dense они обрабатываются слоем Flatten x = layers.Flatten()(inputs) x = layers.Dense(256)(x) x = layers.Dropout(0.5)(x) outputs = layers.Dense(1, activation="sigmoid")(x) model = keras.Model(inputs, outputs) model.compile(loss="binary_crossentropy", optimizer="rmsprop", metrics=["accuracy"] ) callbacks = [ keras.callbacks.ModelCheckpoint( filepath="feature_extraction.keras", save_best_only=True, monitor="val_loss") ] history = model.fit( train_features, train_labels, epochs=20, validation_data=(val_features, val_labels), callbacks=callbacks)
Обучение проходит очень быстро, потому что мы определили только два слоя Dense - одна эпоха длится меньше одной секунды даже при выполнении на CPU.
Посмотрим теперь на графики изменения потерь и точности в процессе обучения (рисунок 1).
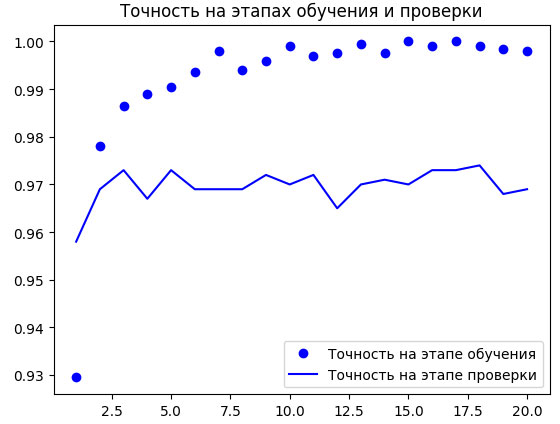
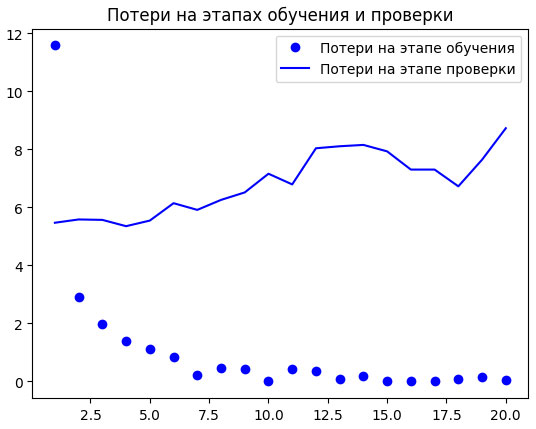
Рис.1. Изменение метрик на этапах проверки и обучения для простого извлечения признаков
Пример 8.22. Построение графиков с результатами
import matplotlib.pyplot as plt acc = history.history["accuracy"] val_acc = history.history["val_accuracy"] loss = history.history["loss"] val_loss = history.history["val_loss"] epochs = range(1, len(acc) + 1) plt.plot(epochs, acc, "bo", label="Точность на этапе обучения") plt.plot(epochs, val_acc, "b", label="Точность на этапе проверки") plt.title("Точность на этапах обучения и проверки") plt.legend() plt.figure() plt.plot(epochs, loss, "bo", label="Потери на этапе обучения") plt.plot(epochs, val_loss, "b", label="Потери на этапе проверки") plt.title("Потери на этапах обучения и проверки") plt.legend() plt.show()
Мы достигли точности, близкой к 97%, - более высокой, чем в предыдущем разделе, где обучали небольшую модель с нуля. Впрочем, это не совсем справедливое сравнение: ImageNet содержит много изображений собак и кошек, а это означает, что взятая нами предварительно обученная модель уже обладает знаниями, необходимыми для решения поставленной задачи. Но так бывает не всегда, когда используются предварительно выученные признаки.
Кроме того, графики показывают, что почти с самого начала стал проявляться эффект переобучения, несмотря на выбор довольно большого коэффициента прореживания. Это объясняется тем, что в данном примере мы не использовали обогащение данных, которое необходимо для предотвращения переобучения на небольших наборах изображений.
На следующем шаге мы рассмотрим выделение признаков с обогащением данных.
