На этом шаге мы рассмотрим особенности реализации такого дообучения.
Другой широко используемый прием повторного использования модели, дополняющий выделение признаков, - дообучение (fine-tuning) (рисунок 1).
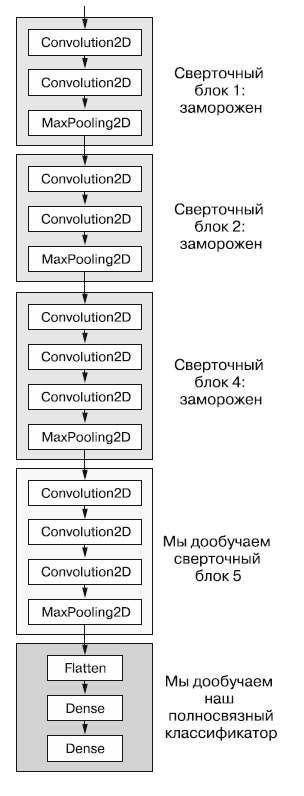
Рис.1. Дообучение последнего сверточного блока сети VGG16
Дообучение заключается в размораживании нескольких верхних слоев замороженной модели, которая использовалась для выделения признаков, и совместном обучении вновь добавленной части модели (в данном случае полносвязного классификатора) и этих верхних слоев. Данный прием называется дообучением, поскольку немного корректирует наиболее абстрактные представления в повторно используемой модели, чтобы сделать их более актуальными для конкретной задачи.
Ранее мы отмечали, что для обучения классификатора, инициализированного случайными значениями, необходимо заморозить сверточную основу сети VGG16. По той же причине дообучить несколько верхних слоев сверточной основы можно только после обучения классификатора. Если классификатор еще не обучен, ошибочный сигнал, распространяющийся по сети в процессе дообучения, окажется слишком велик, и представления, полученные на предыдущем этапе обучения, будут разрушены. Поэтому для дообучения сети нужно выполнить следующие шаги.
- Добавить свою сеть поверх обученной базовой сети.
- Заморозить базовую сеть.
- Обучить добавленную часть.
- Разморозить несколько слоев в базовой сети. (Обратите внимание, что не следует размораживать слои "пакетной нормализации", которые здесь
неактуальны, поскольку в VGG16 таких слоев нет, - мы объясним пакетную нормализацию и покажем ее влияние на дообучение в следующих шагах.)
- Обучить эти слои и добавленную часть вместе.
Мы уже выполнили первые три шага в ходе выделения признаков. Теперь выполним шаг 4: разморозим conv_base и заморозим отдельные слои в ней.
Вспомним, как выглядит наша сверточная основа:
conv_base.summary() Model: "vgg16" Layer (type) Output Shape Param # input_layer (InputLayer) (None, 180, 180, 3) 0 block1_conv1 (Conv2D) (None, 180, 180, 64) 1,792 block1_conv2 (Conv2D) (None, 180, 180, 64) 36,928 block1_pool (MaxPooling2D) (None, 90, 90, 64) 0 block2_conv1 (Conv2D) (None, 90, 90, 128) 73,856 block2_conv2 (Conv2D) (None, 90, 90, 128) 147,584 block2_pool (MaxPooling2D) (None, 45, 45, 128) 0 block3_conv1 (Conv2D) (None, 45, 45, 256) 295,168 block3_conv2 (Conv2D) (None, 45, 45, 256) 590,080 block3_conv3 (Conv2D) (None, 45, 45, 256) 590,080 block3_pool (MaxPooling2D) (None, 22, 22, 256) 0 block4_conv1 (Conv2D) (None, 22, 22, 512) 1,180,160 block4_conv2 (Conv2D) (None, 22, 22, 512) 2,359,808 block4_conv3 (Conv2D) (None, 22, 22, 512) 2,359,808 block4_pool (MaxPooling2D) (None, 11, 11, 512) 0 block5_conv1 (Conv2D) (None, 11, 11, 512) 2,359,808 block5_conv2 (Conv2D) (None, 11, 11, 512) 2,359,808 block5_conv3 (Conv2D) (None, 11, 11, 512) 2,359,808 block5_pool (MaxPooling2D) (None, 5, 5, 512) 0 Total params: 14,714,688 (56.13 MB) Trainable params: 14,714,688 (56.13 MB) Non-trainable params: 0 (0.00 B)
Почему бы не дообучить больше слоев? Почему бы не дообучить всю сверточную основу? Так можно поступить, но имейте в виду следующее.
- Начальные слои в сверточной основе кодируют более обобщенные признаки, пригодные для повторного использования, а более высокие слои кодируют
более конкретные признаки. Намного полезнее донастроить более конкретные признаки, потому что именно их часто нужно перепрофилировать для решения новой
задачи. Ценность дообучения нижних слоев быстро падает с их глубиной.
- Чем больше параметров обучается, тем выше риск переобучения. Сверточная основа имеет 15 миллионов параметров, поэтому было бы слишком
рискованно пытаться дообучить ее целиком на нашем небольшом наборе данных.
То есть в данной ситуации лучшей стратегией будет дообучить только верхние 2-3 слоя сверточной основы. Сделаем это, начав с того места, на котором мы остановились в предыдущем примере.
Пример 8.27. Замораживание всех слоев, кроме заданных
conv_base.trainable = True for layer in conv_base.layers[:-4]: layer.trainable = False
Теперь можно начинать дообучение модели. Для этого используем оптимизатор RMSProp с очень маленькой скоростью обучения. Причина использования низкой скорости обучения заключается в необходимости ограничить величину изменений, вносимых в представления трех дообучаемых слоев. Слишком большие изменения могут повредить эти представления.
Пример 8.28. Дообучение модели
model.compile(loss="binary_crossentropy", optimizer=keras.optimizers.RMSprop(learning_rate=1e-5), metrics=["accuracy"] ) callbacks = [ keras.callbacks.ModelCheckpoint( filepath="fine_tuning.keras", save_best_only=True, monitor="val_loss") ] history = model.fit( train_dataset, epochs=30, validation_data=validation_dataset, callbacks=callbacks)
Закончив обучение, оценим модель на контрольных данных:
model = keras.models.load_model("fine_tuning.keras") test_loss, test_acc = model.evaluate(test_dataset) print(f"Test accuracy: {test_acc:.3f}")
Мы получили точность на уровне 98,5% (и снова вы можете получить другую цифру, с разницей в пределах одного процента). В оригинальном состязании на сайте Kaggle, основанном на этом наборе данных, это был бы один из лучших результатов. Впрочем, сравнивать наши условия с конкурсными не совсем справедливо: мы использовали предварительно обученную модель, уже обладающую знаниями, которые помогали ей отличать кошек от собак, тогда как участники состязания такой возможности не имели.
С другой стороны, благодаря современным методам глубокого обучения нам удалось достичь такого результата, использовав лишь малую часть обучающих данных (около 10%), доступных участникам соревнования. Между обучением на 20 000 и на 2000 образцов огромная разница!
Теперь у вас есть надежный набор инструментов для решения задач классификации изображений, особенно с ограниченным объемом данных.
На следующем шаге мы подведем итоги по изученному материалу.
