На этом шаге мы рассмотрим реализацию этого приема.
Теперь рассмотрим второй прием выделения признаков, более медленный и затратный, но позволяющий использовать обогащение данных в процессе обучения, - объединение модели conv_base с новым полносвязным классификатором и ее полноценное обучение.
Для этого мы сначала заморозим сверточную основу. Замораживание одного или нескольких слоев предотвращает изменение весовых коэффициентов в них в процессе обучения. Если этого не сделать, представления, прежде изученные сверточной основой, изменятся в процессе обучения на новых данных. Так как слои Dense сверху инициализируются случайными значениями, в сети могут произойти существенные изменения весов, фактически разрушив представления, полученные ранее.
В Keras, чтобы заморозить сеть, нужно передать атрибут trainable со значением False.
Пример 8.23. Создание и заморозка сверточной основы
conv_base = keras.applications.vgg16.VGG16(
weights="imagenet",
include_top=False)
conv_base.trainable = False
При передаче в атрибуте trainable значения False список обучаемых весов слоя или модели очищается.
Пример 8.24. Вывод списка обучаемых весов до и после заморозки c
onv_base.trainable = True print("This is the number of trainable weights " "before freezing the conv base:", len(conv_base.trainable_weights)) conv_base.trainable = False print("This is the number of trainable weights " "after freezing the conv base:", len(conv_base.trainable_weights)) This is the number of trainable weights before freezing the conv base: 26 This is the number of trainable weights after freezing the conv base: 0
Теперь создадим новую модель, объединяющую следующее.
- Этап обогащения данных.
- Замороженную сверточную основу.
- Полносвязный классификатор.
Пример 8.25. Добавление этапа обогащения данных и классификатора к сверточной основе
data_augmentation = keras.Sequential(
[
layers.RandomFlip("horizontal"),
layers.RandomRotation(0.1),
layers.RandomZoom(0.2),
]
)
inputs = keras.Input(shape=(180, 180, 3))
# Обогащение данных
x = data_augmentation(inputs)
# Масштабирование входных данных
x = keras.applications.vgg16.preprocess_input(x)
x = conv_base(x)
x = layers.Flatten()(x)
x = layers.Dense(256)(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(loss="binary_crossentropy",
optimizer="rmsprop",
metrics=["accuracy"])
В этом случае обучению будут подвергаться только веса из двух вновь добавленных слоев Dense, то есть всего четыре весовых тензора, по два на слой (главная весовая матрица и вектор смещений). Обратите внимание: чтобы эти изменения вступили в силу, необходимо скомпилировать модель. Если признак обучения весов изменяется после компиляции модели, необходимо снова перекомпилировать модель, иначе это изменение будет игнорироваться.
Давайте начнем обучение модели. Мы добавили этап обогащения данных, поэтому обучение будет длиться намного дольше, прежде чем проявится эффект переобучения, - так что можно увеличить количество эпох, скажем, до 50 .
 Этот прием настолько затратный, что его следует применять только при наличии доступа к GPU (например, к бесплатному GPU в Colab) -
он абсолютно не под силу CPU. Если у вас нет возможности запустить свой код на GPU, то первый путь остается для вас единственным доступным решением.
Этот прием настолько затратный, что его следует применять только при наличии доступа к GPU (например, к бесплатному GPU в Colab) -
он абсолютно не под силу CPU. Если у вас нет возможности запустить свой код на GPU, то первый путь остается для вас единственным доступным решением.
callbacks = [
keras.callbacks.ModelCheckpoint(
filepath="feature_extraction_with_data_augmentation.keras",
save_best_only=True,
monitor="val_loss")
]
history = model.fit(
train_dataset,
epochs=50,
validation_data=validation_dataset,
callbacks=callbacks)
Снова построим графики изменения метрик (рисунок 1).
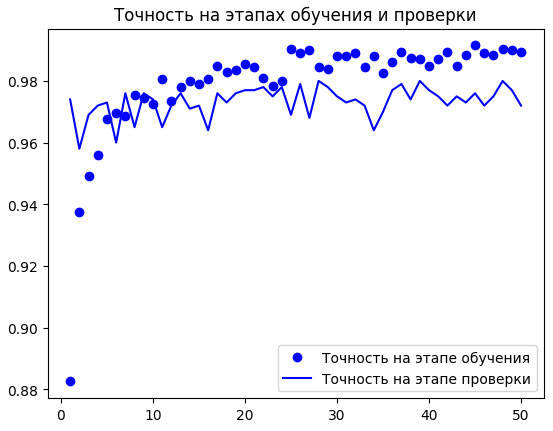
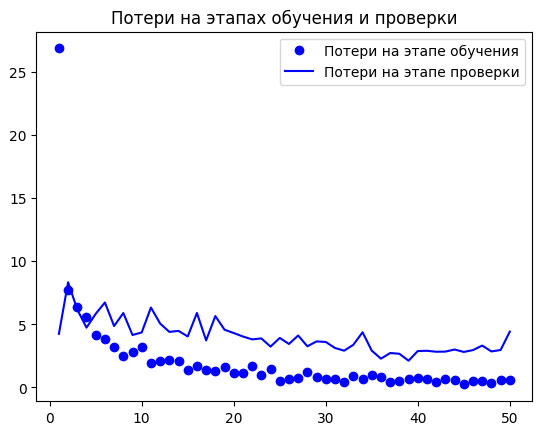
Рис.2. Изменение метрик на этапах проверки и обучения для извлечения признаков с обогащением данных
Как видите, мы превысили уровень точности 98 % на этапе проверки. Это серьезное улучшение по сравнению с предыдущей моделью.
Проверим точность на контрольных данных.
Пример 8.26. Оценка модели на контрольном наборе данных
test_model = keras.models.load_model(
"feature_extraction_with_data_augmentation.keras")
test_loss, test_acc = test_model.evaluate(test_dataset)
print(f"Test accuracy: {test_acc:.3f}")
Блокнот с этим примером можно взять здесь.
Мы получили точность на контрольных данных 97,5% . По сравнению с предыдущей моделью это довольно скромное улучшение - что немного разочаровывает, особенно учитывая, насколько улучшилась точность на проверочных данных. Точность модели всегда зависит от набора образцов, на котором выполняется ее оценка! Некоторые наборы могут содержать образцы, более трудные для распознавания, поэтому хорошие результаты на одном наборе не обязательно будут подтверждаться на всех других наборах.
На следующем шаге мы рассмотрим дообучение предварительно обученной модели.
