На этом шаге мы рассмотрим преобразование файла CSV.
Прежде чем углубиться в рассмотрение деталей и приступить к написанию кода, загрузим небольшое подмножество набора данных, содержащихся в базе MNIST. Файлы данных MNIST имеют очень большой размер, тогда как работать с небольшими наборами значительно удобнее, поскольку это позволит нам экспериментировать, разрабатывать и испытывать свой код, что было бы затруднительно в случае длительных расчетов из-за большого объема обрабатываемых данных. Когда бы отработаем алгоритм и будем удовлетворены созданным кодом, можно будет вернуться к полному набору данных.
Ниже приведены ссылки на меньшие наборы MNIST, также подготовленные в формате CSV.
- 10 записей из тестового набора данных MNIST: https://raw.githubusercontent.com/makeyourownneuralnetwork/makeyourownneuralnetwork/master/mnist_dataset/mnist_test_10.csv или здесь;
- 100 записей из тренировочного набора данных MNIST: https://raw.githubusercontent.com/makeyourownneuralnetwork/makeyourownneuralnetwork/master/mnist_dataset/mnist_train_100.csv или здесь.
Сохраните файлы в локальной папке, выбрав ее по своему усмотрению.
Прежде чем с этими данными можно будет что-либо сделать, например построить график или обучить с их помощью нейронную сеть, необходимо обеспечить доступ к ним из кода на языке Python.
Открытие файлов и получение их содержимого в Python не составляет большого труда. Лучше всего показать, как это делается, на конкретном примере. Взгляните на следующий код.
data_file = open("D:/NN/mnist_train_100.csv", 'r') data_list = data_file.readlines() data_file.close()
Здесь всего три строки кода. Обсудим каждую из них по отдельности.
Первая строка открывает файл с помощью функции open(). Вы видите, что в качестве первого из параметров ей передается имя файла. На самом деле это не просто имя файла mnist_train_100.csv, а весь путь доступа к нему, включая каталог (папку), в котором он находится. Второй параметр необязательный и сообщает Python, как мы хотим работать с файлом. Буква "r" означает, что мы хотим открыть файл только для чтения, а не для записи. Тем самым мы предотвращаем любое непреднамеренное изменение или удаление файла. Если мы попытаемся осуществить запись в этот файл или изменить его, Python не позволит этого сделать и выдаст ошибку. А что это за переменная data_file? Функция open() создает дескриптор (указатель), играющий роль ссылки на открываемый файл, и мы присваиваем его переменной data_file. Когда файл открыт, любые последующие действия с ним, например чтение, осуществляются через этот дескриптор.
Следующая строка проще. Мы используем функцию readlines(), ассоциированную с дескриптором файла data_file, для чтения всех строк содержимого файла в переменную data_list. Эта переменная содержит список, каждый элемент которого является строкой, представляющей строку файла. Это очень удобно, поскольку мы можем переходить к любой строке файла так же, как к конкретным записям в списке. Таким образом, data_list[0] - это первая запись, a data_list[9] - десятая и т.п.
Кстати, вполне возможно, что некоторые люди не рекомендовали вам использовать функцию readlines(), поскольку она считывает весь файл в память. Наверное, они советовали вам считывать по одной строке за раз, выполнять всю необходимую обработку для этой строки и лишь затем переходить к следующей. Нельзя сказать, что они неправы. Действительно, гораздо эффективнее работать поочередно с каждой строкой, а не считывать в память весь файл целиком. Однако наши файлы невелики, и использование функции readlines() значительно упрощает код, а для нас простота и ясность очень важны, поскольку мы изучаем Python.
Последняя строка закрывает файл. Считается хорошей практикой закрывать файлы и другие ресурсы после их использования. Если же оставлять их открытыми, то это может приводить к возникновению проблем. Что за проблемы? Некоторые программы могут отказываться осуществлять запись в файл, открытый в другом месте, если это приводит к несогласованности. В противном случае это напоминало бы ситуацию, когда два человека пытаются одновременно записывать разные тексты на одном и том же листе бумаги. Иногда компьютер может заблокировать файл во избежание такого рода конфликтов. Если не оставить за собой порядок после того, как необходимость в использовании файла уже отпала, у вас может накопиться много заблокированных файлов. По крайней мере, закрыв файл, вы предоставите компьютеру возможность освободить память, занимаемую уже ненужными данными.
Создайте новый пустой блокнот, выполните представленный ниже код и посмотрите, что произойдет, если попытаться вывести элементы списка.
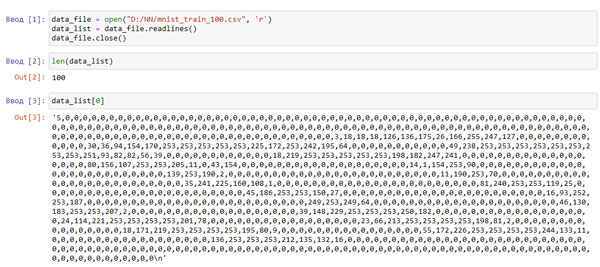
Рис.1. Результат чтения из файла
Вы видите, что длина списка равна 100. Функция Python len() сообщает о размере списка. Вы также можете видеть содержимое первой записи, data_list[0]. Первое число, 5, - это маркер, тогда как остальные 784 числа - это цветовые коды пикселей, из которых состоит изображение. Бели вы внимательно присмотритесь, то заметите, что их значения не выходят за пределы диапазона 0 до 255. Вы можете взглянуть на другие записи, чтобы проверить, выполняется ли это условие и для них. Вы убедитесь в том, что так оно и есть: значения кодов всех цветов попадают в диапазон чисел от 0 до 255.
Ранее приводился пример графического отображения прямоугольного массива чисел с использованием функции imshow(). То же самое мы хотим сделать и в данном случае, но для этого нам нужно преобразовать список чисел, разделенных запятыми, в подходящий массив. Это можно сделать в соответствии со следующей процедурой:
- разбить длинную текстовую строку значений, разделенных запятыми, на отдельные значения, используя символ запятой в качестве разделителя;
- проигнорировать первое значение, являющееся маркером, извлечь оставшиеся 28 * 28 = 784 значения и преобразовать их в массив, состоящий из 28 строк и 28 столбцов;
- отобразить массив!
И вновь, проще всего показать соответствующий простой код на Python и уже после этого подробно рассмотреть, что в нем происходит.
Прежде всего, мы не должны забывать о необходимости импортировать библиотеки расширений Python для работы с массивами и графикой.
import numpy import matplotlib.pyplot %matplotlib inline
А теперь взгляните на следующие три строки кода. Переменные окрашены различными цветами таким образом, чтобы было понятно, где и какие данные используются.
all_values = data_list[0].split(',') image_array = numpy.asfarray(all_values[1:]).reshape((28, 28)) matplotlib.pyplot.imshow(image_array, cmap='Greys', interpolation='None')
В первой строке длинная первая запись data_list[0], которую мы только что выводили, разбивается на отдельные значения с использованием запятой в качестве разделителя. Это делается с помощью функции split(), параметр которой определяет символ-разделитель. Результат помещается в переменную all_values. Можете вывести эти значения на экран и убедиться в том, что эта переменная действительно содержит нужные значения в виде длинного списка Python.
Следующая строка кода выглядит чуть более сложной, поскольку в ней происходит сразу несколько вещей. Начнем с середины. Запись списка в виде all_valuas[1:] указывает на то, что берутся все элементы списка за исключением первого. Тем самым мы игнорируем первое значение, играющее роль маркера, и берем лишь остальные 784 элемента, numpy.asfarray() - это функция библиотеки numpy, преобразующая текстовые строки в реальные числа и создающая массив этих чисел. Постойте-ка, но почему текстовые строки преобразуются в числа? Если файл был прочитан как текстовый, то каждая строка или запись все еще остается текстом. Извлечение из них отдельных элементов, разделенных запятыми, также дает текстовые элементы. Например, этим текстом могли бы быть слова "apple", "orangel23" или "567". Текстовая строка "567" - это не то же самое, что число 567. Именно поэтому мы должны преобразовывать текстовые строки в числа, даже если эти строки выглядят как числа. Последний фрагмент инструкции - .reshape ((28, 28)) - гарантирует, что список будет сформирован в виде квадратной матрицы размером 28x28. Результирующий массив такой же размерности получает название image_array. Ух! Как много интересного всего лишь в одной строке кода!
Третья строка просто выводит на экран массив image_array с помощью функции imshow(), аналогично тому, с чем вы уже сталкивались. На этот раз мы выбрали цветовую палитру оттенков серого с помощью параметра cmap='Greys' для лучшей различимости рукописных символов.
Результат работы кода представлен ниже.
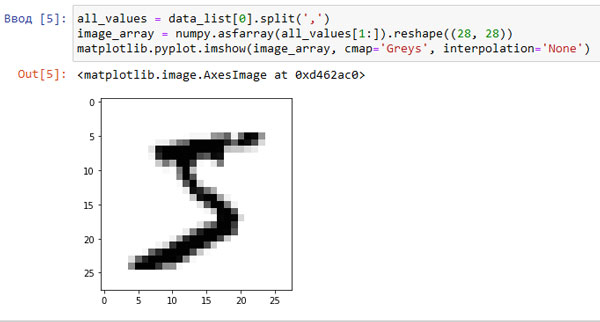
Рис.2. Вывод цифры "5"
Вы видите графическое изображение цифры "5", на что и указывал маркер. Если мы выберем следующую запись, data_list[1] с маркером 0, то получим показанное ниже изображение.
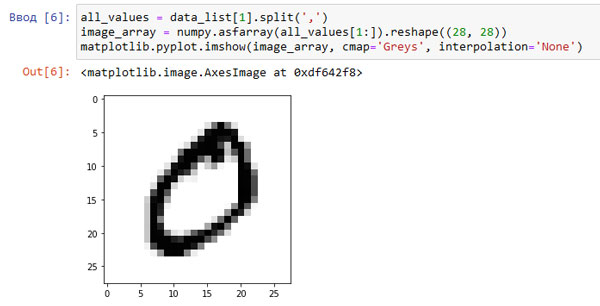
Рис.2. Вывод цифры "0"
Глядя на это изображение, вы с уверенностью можете сказать, что этой рукописной цифре действительно соответствует цифра 0.
На следующем шаге мы рассмотрим подготовку тренировочных данных MNIST.
