На этом шаге мы рассмотрим получение дополнительных данных для тренировки путем вращения оригинала.
Оценивая тренировочные данные MNIST, следует сказать, что они содержат довольно богатый набор рукописных начертаний цифр. В нем встречается множество видов почерка и стилей, причем как хороших, так и плохих.
Нейронная сеть должна учиться на как можно большем количестве всевозможных вариантов написания цифр. Удачно то, что в этот набор входит также множество форм написания цифры "4". Одни из них искусственно сжаты, другие растянуты, некоторые повернуты, в одних верхушка цифры разомкнута, в других сомкнута.
Разве не будет полезно создать дополнительные варианты написания и использовать их в качестве тренировочных примеров? Как это сделать? Нам трудно собрать коллекцию из тысячи дополнительных примеров рукописного написания той или иной цифры. Вернее, мы могли бы попытаться, но это стоило бы нам огромных усилий.
Но ведь ничто не мешает нам взять существующие примеры и создать на их основе новые, повернув цифры по часовой стрелке или против, скажем, на 10 градусов. В этом случае мы могли бы создать по два дополнительных примера для каждого из уже имеющихся. Мы могли бы создать гораздо больше примеров, вращая образцы на разные углы, но мы ограничимся углами +10 и -10 градусов, чтобы посмотреть, как работает эта идея.
И вновь большую помощь в этом нам окажут расширения и библиотеки Python. Функция scipy.ndimage.interpolation.rotate() поворачивает изображение, представленное массивом, на заданный угол, а это именно то, что нам нужно. Описание функции можно найти здесь: https://docs.scipy.org/doc/scipy-0.16.0/reference/generated/scipy.ndimage.interpolation.rotate.html.
Вспомните, что наши входные значения представляют собой одномерный список длиной 784 элемента, поскольку мы спроектировали нашу нейронную сеть таким образом, чтобы она принимала длинный список входных сигналов. Мы должны реорганизовать этот список в массив размерностью 28x28, чтобы повернуть изображение, а затем проделать обратную операцию по преобразованию массива в список из 784 входных сигналов, которые мы подадим на вход нейронной сети.
В приведенном ниже коде показан пример использования функции scipy.ndimage.interpolation.rotate() в предположении, что у нас уже имеется массив scaled_input, о котором шла речь ранее.
# создание повернутых на некоторый угол вариантов изображений # повернуть на 10 градусов против часовой стрелки inputs_plus10_img = bscipy.ndimage.interpolation.rotate(scaled_input.reshape(28, 28), 10, cval=0.01, reshape=False) # повернуть на 10 градусов по часовой стрелке inputs_minus10_img = scipy.ndimage.interpolation.rotate(scaled_input.reshape(28, 28), -10, cval=0.01, reshape=False)
В этом коде первоначальный массив scaled_input преобразуется в массив размерностью 28x28. Параметр reshape=False сдерживает излишнюю рьяность библиотеки в ее желании быть как можно более полезной и сжать изображение таким образом, чтобы после вращения все оно уместилось в массиве и ни один его пиксель не был отсечен. Параметр cval - это значение, используемое для заполнения элементов массива, которые не существовали в исходном массиве, но теперь появились. Мы откажемся от используемого по умолчанию значения 0,0 и заменим его значением 0,01, поскольку во избежание подачи на вход нейронной сети нулей мы используем смещенный диапазон входных значений.
Запись 6 (седьмая по счету) малого тренировочного набора MNIST содержит рукописное начертание цифры "1". Вот как выглядят ее исходное изображение и две его повернутые вариации, полученные с помощью нашего кода.
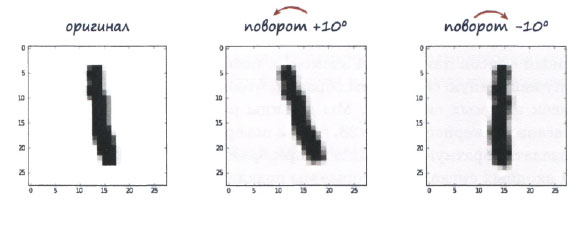
Результаты очевидны. Версия исходного изображения, повернутая на +10 градусов, является примером почерка человека, "заваливающего" текст влево. Еще более интересна версия оригинала, повернутая на -10 градусов, т.е. по часовой стрелке. Эта версия располагается даже ровнее по сравнению с оригиналом и в некотором смысле более представительна в качестве изображения для обучения.
На следующем шаге мы закончим изучение этого вопроса.
