На этом шаге мы рассмотрим применение этого алгоритма к анализу лиц.
Теперь давайте применим NMF к набору данных Labeled Faces in the Wild, который мы использовали ранее. Основной параметр NMF - количество извлекаемых компонент. Как правило, количество извлекаемых компонент меньше количества входных характеристик (в противном случае, данные можно объяснить, представив каждый пиксель отдельной компонентой).
Во-первых, давайте выясним, как количество компонент влияет на качество восстановления данных с помощью NMF (рисунок 1):
[In 34]:
mglearn.plots.plot_nmf_faces(X_train, X_test, image_shape)
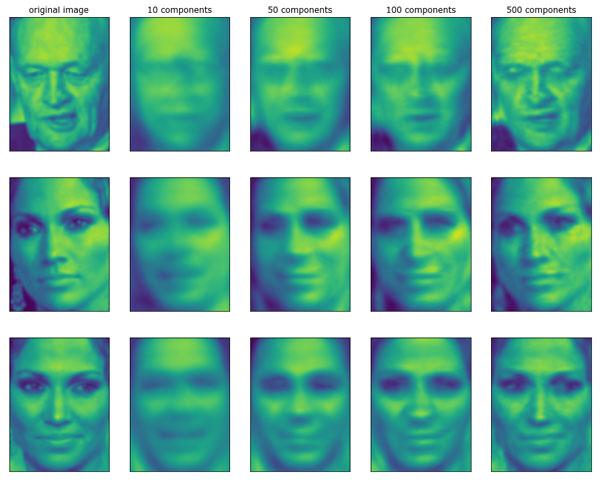
Рис.1. Реконструкция трех изображений лица с помощью постепенного увеличения числа компонент
Качество обратно преобразованных данных аналогично качеству, полученному с помощью PCA, но немного хуже. Это вполно ожидаемо, поскольку PCA находит оптимальные направления с точки зрения реконструкции данных. NMF же, как правило, используется не из-за своей способности реконструировать или представлять данные, а скорее из-за того, что позволяет находить интересные закономерности в данных.
Для начала давайте попробуем извлечь лишь несколько компонент (скажем, 15). Рисунок 2 показывает результат:
[In 35]: from sklearn.decomposition import NMF nmf = NMF(n_components=15, random_state=0) nmf.fit(X_train) X_train_nmf = nmf.transform(X_train) X_test_nmf = nmf.transform(X_test) fix, axes = plt.subplots(3, 5, figsize=(15, 12), subplot_kw={'xticks': (), 'yticks': ()}) for i, (component, ax) in enumerate(zip(nmf.components_, axes.ravel())): ax.imshow(component.reshape(image_shape)) ax.set_title("{}. component".format(i))

Рис.2. Компоненты, найденные NMF для набора лиц (использовалось 15 компонент)
Все эти компоненты являются положительными и поэтому похожи на прототипы лиц гораздо больше, чем компоненты PCA, показанные на рисунке 2 90 шага. Например, четко видно, что компонента 3 показывает лицо, немного повернутое вправо, тогда как компонента 7 показывает лицо, немного повернутое влево. Давайте посмотрим на изображения, для которых эти компоненты имеют наибольшие значения (показаны на рисунках 3 и 4):
[In 36]: compn = 3 # сортируем по 3-й компоненте, выводим первые 10 изображений inds = np.argsort(X_train_nmf[:, compn])[::-1] fig, axes = plt.subplots(2, 5, figsize=(15, 8), subplot_kw={'xticks': (), 'yticks': ()}) for i, (ind, ax) in enumerate(zip(inds, axes.ravel())): ax.imshow(X_train[ind].reshape(image_shape)) compn = 7 # сортируем по 7-й компоненте, выводим первые 10 изображений inds = np.argsort(X_train_nmf[:, compn])[::-1] fig, axes = plt.subplots(2, 5, figsize=(15, 8), subplot_kw={'xticks': (), 'yticks': ()}) for i, (ind, ax) in enumerate(zip(inds, axes.ravel())): ax.imshow(X_train[ind].reshape(image_shape))

Рис.3. Лица с большим коэффициентом компоненты 3

Рис.4. Лица с большим коэффициентом компоненты 7
Как и следовало ожидать, лица с высоким коэффициентом компоненты 3 - это лица, смотрящие вправо (рисунок 3), тогда как лица с высоким коэффициентом компоненты 7 смотрят влево (рисунок 4). Как уже упоминалось ранее, выделение паттернов, аналогичных рассматриваемым изображениям, лучше всего работает в отношении данных с аддитивной структурой, включая аудиоданные, данные экспрессии генов и текстовые данные. Давайте рассмотрим еще один пример на основе синтетических данных, чтобы увидеть, как это будет выглядеть.
На следующем шаге мы закончим изучение этого вопроса.
