На этом шаге мы рассмотрим назначение и использование этого алгоритма.
Хотя PCA часто выступает в качестве приоритетного метода, преобразующего данные таким образом, что можно визуализировать их с помощью диаграммы рассеяния, сам характер метода (вращение данных, а затем удаление направлений, объясняющих незначительную дисперсию данных) ограничивает его полезность, как мы уже убедились на примере диаграммы рассеяния для набора данных Labeled Faces in the Wild. Существует класс алгоритмов визуализации, называемых алгоритмами множественного обучения (manifold learning algorithms), которые используют гораздо более сложные графические представления данных и позволяют получить визуализации лучшего качества. Особенно полезным является алгоритм t-SNE.
Алгоритмы множественного обучения в основном направлены на визуализацию и поэтому редко используются для получения более двух новых характеристик. Некоторые из них, в том числе t-SNE, создают новое представление обучающих данных, но при этом не осуществляют преобразования новых данных. Это означает, что данные алгоритмы нельзя применить к тестовому набору, они могут преобразовать лишь те данные, на которых они были обучены. Множественное обучение может использоваться для разведочного анализа данных, но редко используется в тех случаях, когда конечной целью является применение модели машинного обучения с учителем. Идея, лежащая в основе алгоритма t-SNE, заключается в том, чтобы найти двумерное представление данных, сохраняющее расстояния между точками наилучшим образом. t-SNE начинает свою работу со случайного двумерного представления каждой точки данных, а затем пытается сблизить точки, которые в пространстве исходных признаков находятся близко друг к другу, и отдаляет друг от друга точки, которые находятся далеко друг от друга. При этом t-SNE уделяет большее внимание сохранению расстояний между точками, близко расположенными друг к другу. Иными словами, он пытается сохранить информацию, указывающую на то, какие точки являются соседями друг другу.
Мы применим алгоритм множественного обучения t-SNE к набору данных рукописных цифр, который включен в scikit-learn.
 Не следует путать с гораздо большим набором данных MNIST.
Не следует путать с гораздо большим набором данных MNIST.Каждая точка данных в этом наборе является изображением цифры в градациях серого. Рисунок 1 показывает примеры изображений для каждого класса:
[In 42]: from sklearn.datasets import load_digits digits = load_digits() fig, axes = plt.subplots(2, 5, figsize=(10, 5), subplot_kw={'xticks':(), 'yticks': ()}) for ax, img in zip(axes.ravel(), digits.images): ax.imshow(img)
Рис.1. Примеры изображений из набора данных digits
Давайте используем PCA для визуализации данных, сведя их к двум измерениям. Мы построим график первых двух главных компонент и отметим цветом класс каждой точки (рисунок 2):
[In 43]: # строим модель PCA pca = PCA(n_components=2) pca.fit(digits.data) # преобразуем данные рукописных цифр к первым двум компонентам digits_pca = pca.transform(digits.data) colors = ["#476A2A", "#7851B8", "#BD3430", "#4A2D4E", "#875525", "#A83683", "#4E655E", "#853541", "#3A3120", "#535D8E"] plt.figure(figsize=(10, 10)) plt.xlim(digits_pca[:, 0].min(), digits_pca[:, 0].max()) plt.ylim(digits_pca[:, 1].min(), digits_pca[:, 1].max()) for i in range(len(digits.data)): # строим график, где цифры представлены символами вместо точек plt.text(digits_pca[i, 0], digits_pca[i, 1], str(digits.target[i]), color = colors[digits.target[i]], fontdict={'weight': 'bold', 'size': 9}) plt.xlabel("Первая главная компонента") plt.ylabel("Вторая главная компонента")
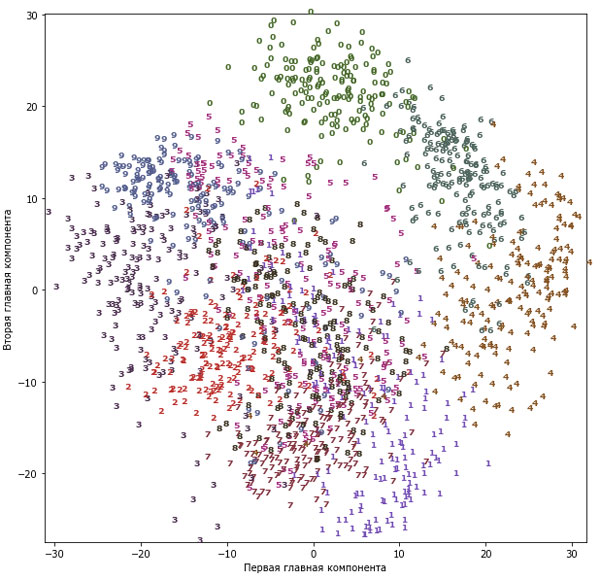
Рис.2. Диаграмма рассеяния для набора данных digits, использующая первые две главные компоненты
Здесь мы вывели фактические классы цифр в виде символов, чтобы визуально показать расположение каждого класса. Цифры 0, 6 и 4 относительно хорошо разделены с помощью первых двух главных компонент, хотя по-прежнему перекрывают друг друга. Большинство остальных цифр значительно перекрывают друг друга.
Давайте применим t-SNE к этому же набору данных и сравним результаты. Поскольку t-SNE не поддерживает преобразование новых данных, в классе TSNE нет метода transform(). Вместо этого мы можем вызвать метод fit_transform(), который построит модель и немедленно вернет преобразованные данные (см. рисунок 3):
[In 44]: from sklearn.manifold import TSNE tsne = TSNE(random_state=42) # используем метод fit_transform вместо fit, т.к. класс TSNE не использует метод transform digits_tsne = tsne.fit_transform(digits.data)
[In 45]: plt.figure(figsize=(10, 10)) plt.xlim(digits_tsne[:, 0].min(), digits_tsne[:, 0].max() + 1) plt.ylim(digits_tsne[:, 1].min(), digits_tsne[:, 1].max() + 1) for i in range(len(digits.data)): # строим график, где цифры представлены символами вместо точек plt.text(digits_tsne[i, 0], digits_tsne[i, 1], str(digits.target[i]), color = colors[digits.target[i]], fontdict={'weight': 'bold', 'size': 9}) plt.xlabel("t-SNE признак 0") plt.xlabel("t-SNE признак 1")
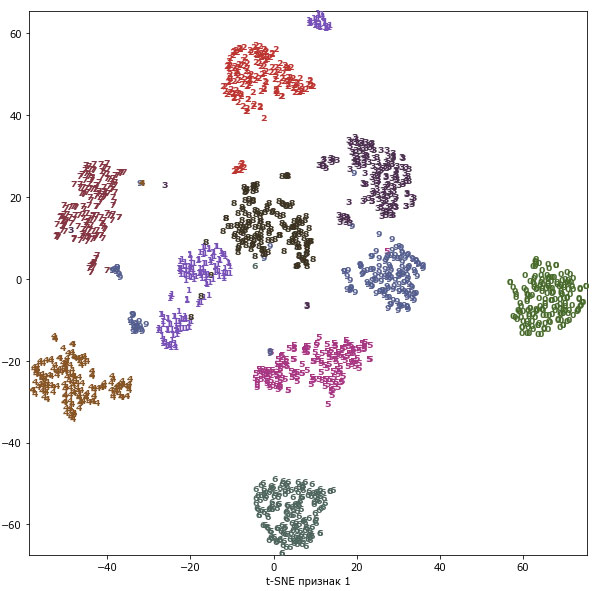
Рис.3. Диаграмма рассеяния для набора данных digits, которая использует первые две главные компоненты, найденные с помощью t-SNE
Результат, полученный с помощью t-SNE, весьма примечателен. Все классы довольно четко разделены. Единицы и девятки в некоторой степени распались, однако большинство классов образуют отдельные сплоченные группы. Имейте в виду, что этот метод не использует информацию о метках классов: он является полностью неконтролируемым. Тем не менее он может наити двумерное представление данных, которое четко разграничивает классы, используя лишь информацию о расстояниях между точками данных в исходном пространстве.
Алгоритм t-SNE имеет некоторые настраиваемые параметры, хотя, как правило, дает хорошее качество, когда используются настроики по умолчанию. Вы можете поэкспериментировать с параметрами perplexity и early_exaggeration, но эффекты от их применения обычно незначительны.
Архив блокнота со всеми вычислениями, выполненными на 82-96 шагах, можно взять здесь.
Со следующего шага мы начнем рассматривать кластеризацию.
