На этом шаге мы рассмотрим, как это можно сделать.
В примере c набором данных adult категориальные переменные были закодированы в виде строк. С одной стороны, это чревато орфографическими ошибками, но, с другой стороны, это позволяет четко отнести признак к категориальной переменной. Часто для удобства хранения или из-за способа сбора данных категориальные переменные кодируются в виде целых чисел. Например, представьте, что данные переписи, представленные в наборе adult, были собраны с помощью анкеты, и ответы, касающиеся типа занятости (workclass), были записаны как 0 (первый пункт отмечен галочкой), 1 (второй пункт отмечен галочкой), 2 (третий пункт отмечен галочкой) и так далее. Теперь столбец будет содержать цифры от 0 до 8, а не строки типа "Private", и если кто-то посмотрит на таблицу, представляющую набор данных, он не сможет с уверенностью отличить непрерывную переменную от категориальной. Хотя мы знаем, что цифры указывают на тип занятости, ясно, что все они соответствуют совершенно различным состояниям и их не следует моделировать с помощью одной непрерывной переменной.
 Категориальные признаки часто кодируются с помощью целых чисел. Тот факт, что для кодировки используются числа, вовсе не означает, что они должны обрабатываться как непрерывные признаки.
Не всегда ясно, следует ли обрабатывать целочисленные значения признаков как непрерывные или дискретные (а также преобразованные с помощью прямого кодирования). Если кодируемые
значения не упорядочены (как в примере с workclass), признак должен рассматриваться как дискретный. В остальных случаях, например, когда признак представляет собой пятизвездочный
рейтинг, выбор оптимальной схемы кодирования зависит от конкретной задачи и данных, а также используемого алгоритма машинного обучения.
Категориальные признаки часто кодируются с помощью целых чисел. Тот факт, что для кодировки используются числа, вовсе не означает, что они должны обрабатываться как непрерывные признаки.
Не всегда ясно, следует ли обрабатывать целочисленные значения признаков как непрерывные или дискретные (а также преобразованные с помощью прямого кодирования). Если кодируемые
значения не упорядочены (как в примере с workclass), признак должен рассматриваться как дискретный. В остальных случаях, например, когда признак представляет собой пятизвездочный
рейтинг, выбор оптимальной схемы кодирования зависит от конкретной задачи и данных, а также используемого алгоритма машинного обучения.
Функция get_dummies() в pandas обрабатывает все числа как непрерывные значения и не будет создавать дамми-переменные для них. Чтобы обойти эту проблему, вы можете либо воспользоваться OneHotEncoder в scikit-learn (указав, какие переменные являются непрерывными, а какие - дискретными), либо преобразовать столбцы с числами, содержащиеся в дата-фрейме, в строки. Чтобы проиллюстрировать это, давайте создадим объект DataFrame с двумя столбцами, один из которых содержит строки, а другой - целые числа:
[In 8]: # создаем дата-фрейм с признаком, который принимает целочисленные значения, # и категориальным признаком, у которой значения являются строками demo_df = pd.DataFrame({'Целочисленный признак': [0, 1, 2, 1], 'Категориальный признак': ['socks', 'fox', 'socks', 'box']}) display(demo_df)
Рисунок 1 показывает результат.
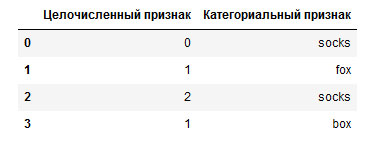
Рис.1. Дата-фрейм, содержащий категориальный строковый признак и целочисленный признак
Функция get_dummies() закодирует лишь строковый признак, тогда как целочисленный признак оставит без изменений, как это видно на рисунке 2:
[In 9]:
pd.get_dummies(demo_df)

Рис.2. Данные из рисунка 1, преобразованные с помощью прямого кодирования, целочисленный признак остался без изменений
Если вы хотите создать дамми-переменные для столбца "Целочисленный признак", вы можете явно указать столбцы, которые нужно закодировать, с помощью параметра columns. И тогда оба признака будут обработаны как категориальные переменные (см. рисунок 3):
[In 10]: demo_df['Целочисленный признак'] = demo_df['Целочисленный признак'].astype(str) pd.get_dummies(demo_df, columns=['Целочисленный признак', 'Категориальный признак'])

Рис.3. Данные рисунка 1, преобразованные с помощью прямого кодирования, закодированы целочисленный и строковый признаки
На следующем шаге мы рассмотрим биннинг, дискретизацию, линейные модели и деревья.
