На этом шаге мы рассмотрим особенности конструирования такой модели.
Входные данные представлены векторами, а метки - скалярами (единицами и нулями): это самый простой набор данных, какой можно встретить. С задачами подобного вида прекрасно справляются модели, организованные как простой стек полносвязных (Dense) слоев с операцией активации relu.
В отношении такого стека слоев Dense требуется принять два важных архитектурных решения:
- сколько слоев использовать;
- сколько скрытых нейронов выбрать для каждого слоя.
В следующем разделе вы познакомитесь с формальными принципами, помогающими сделать правильный выбор. А пока поступим так:
- мы возьмем два промежуточных слоя с 16 нейронами в каждом;
- третий слой будет выводить скалярное значение - оценку направленности текущего отзыва.
На рисунке 1 показано, как выглядит модель.
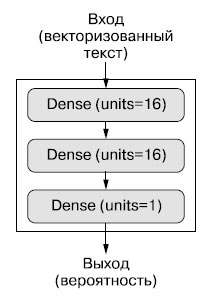
Рис.1.Трехслойная модель
Реализация этой модели с использованием Keras отражена в примере 4.4 - она напоминает пример MNIST, который мы видели раньше.
Пример 4.4. Определение модели
from tensorflow import keras from tensorflow.keras import layers model = keras.Sequential([ layers.Dense(16, activation="relu"), layers.Dense(16, activation="relu"), layers.Dense(1, activation="sigmoid") ])
Первым аргументом каждому слою Dense передается количество нейронов в этом слое: размерность пространства представления слоя. Как рассказывалось ранее, каждый такой слой Dense с функцией активации relu реализует следующую цепочку тензорных операций:
output = relu(dot(input, W) + b)
Наличие 16 нейронов означает, что весовая матрица W будет иметь форму (input_dimension, 16): скалярное произведение на W спроецирует входные данные в 16-мерное пространство представлений (затем будет произведено сложение с вектором смещений b и выполнена операция relu). Размерность пространства представлений можно интерпретировать как "степень свободы модели при изучении внутренних представлений". Большее количество скрытых нейронов (большая размерность пространства представлений) позволяет модели обучаться на более сложных представлениях, но при этом увеличивается вычислительная стоимость модели, что может привести к выявлению нежелательных шаблонов (которые могут повысить качество классификации обучающих данных, но не контрольных).
Промежуточному слою понадобится операция relu в качестве функции активации, а последний слой будет использовать сигмоидную функцию активации и выводить вероятность (оценку вероятности, между 0 и 1, того, что образец относится к классу 1, то есть насколько он близок к положительному отзыву). Функция relu (rectified linear unit - блок линейной ректификации) используется для преобразования отрицательных значений в ноль (рисунок 2), а сигмоидная функция рассредоточивает произвольные значения по интервалу [0, 1] (рисунок 3), возвращая значения, которые можно интерпретировать как вероятность.
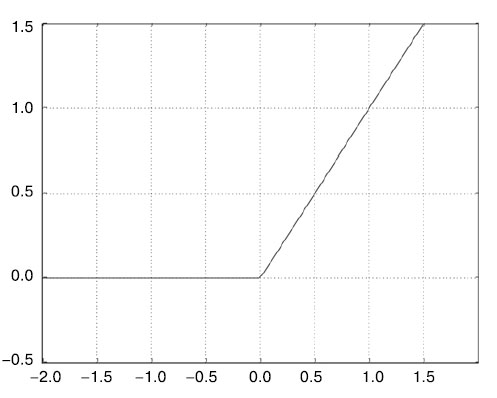
Рис.2. Функция блока линейной ректификации
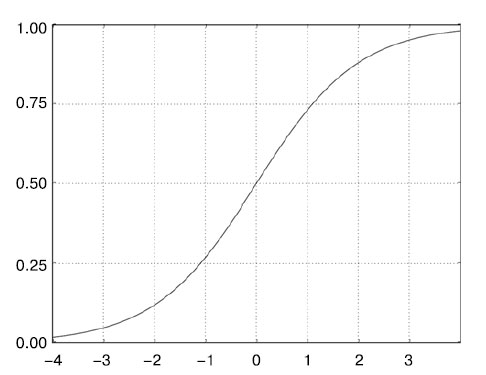
Рис.3. Сигмоидная функция
Наконец, нужно выбрать функцию потерь и оптимизатор. Так как перед нами стоит задача бинарной классификации и результатом работы модели является вероятность (наша модель заканчивается слоем с единственным нейроном и сигмоидной функцией активации), предпочтительнее использовать функцию потерь binary_crossentropy. Это не единственный приемлемый выбор: можно также задействовать, например, mean_squared_error. Однако перекрестная энтропия обычно предпочтительнее, когда результатами работы моделей являются вероятности. Перекрестная энтропия (crossentropy) - это термин из области теории информации, обозначающий меру расстояния между распределениями вероятностей, или в данном случае - между фактическими данными и предсказаниями.
Что такое функции активации и зачем они нужны
Без функции активации, такой как relu (также называемой фактором нелинейности), слой Dense будет состоять из двух линейных операций - скалярного произведения и сложения:
output = dot(W, input) + b
Такой слой сможет обучаться только на линейных (аффинных) преобразованиях входных данных: пространство гипотез слоя было бы совокупностью всех возможных линейных преобразований входных данных в 16-мерное пространство. Такое пространство гипотез слишком ограниченно, и наложение нескольких слоев представлений друг на друга не приносило бы никакой выгоды, потому что глубокий стек линейных слоев все равно реализует линейную операцию: добавление новых слоев не расширяет пространства гипотез. Чтобы получить доступ к более обширному пространству гипотез, дающему дополнительные выгоды от увеличения глубины представлений, необходимо применить нелинейную функцию, или функцию активации. Функция активации relu - самая популярная в глубоком обучении, однако на выбор имеется еще несколько функций активации с немного странными на первый взгляд именами: prelu, elu и т. д.
Что касается выбора оптимизатора, то в этой модели мы будем использовать rmsprop - хороший вариант по умолчанию для большинства задач.
Теперь настроим модель, передав ей оптимизатор rmsprop и функцию потерь binary_crossentropy. Обратите внимание, что мы также задали мониторинг точности во время обучения.
Пример 4.5. Компиляция модели
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
На следующем шаге мы рассмотрим проверку решения.
