На этом шаге мы рассмотрим, как влияет размер сети на процесс обучения.
Вы уже знаете, что слишком маленькие модели не подвержены переобучению. Самый простой способ предотвратить переобучение - уменьшить размер модели, иными словами, количество изучаемых параметров в модели (определяется количеством слоев и количеством нейронов в каждом слое). Модель с ограниченными ресурсами не сможет просто запомнить обучающие данные, поэтому для минимизации потерь ей придется прибегнуть к изучению сжатых представлений, обладающих прогнозирующей способностью в отношении целей, - это нам как раз и требуется. В то же время модель должна иметь достаточное количество параметров, чтобы не возник эффект недообучения: помните, она не должна испытывать недостатка в ресурсах для запоминания. Важно найти компромисс между слишком большой и недостаточной емкостью.
К сожалению, нет волшебной формулы для определения правильного числа слоев или правильного размера каждого слоя. Вам придется оценить множество разных архитектур (на вашей проверочной (но не на контрольной!) выборке, конечно), чтобы определить правильный размер модели для ваших данных. В общем случае процесс поиска подходящего размера модели должен начинаться с относительно небольшого количества слоев и параметров; затем следует постепенно увеличивать размеры слоев и их количество, пока не произойдет увеличение потерь на проверочных данных.
Давайте опробуем этот подход на сети, выполняющей классификацию отзывов к фильмам. В примере 5.10 представлена исходная модель.
Пример 5.10. Исходная модель
from tensorflow.keras.datasets import imdb from tensorflow import keras from tensorflow.keras import layers import numpy as np (train_data, train_labels), _ = imdb.load_data(num_words=10000) def vectorize_sequences(sequences, dimension=10000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1. return results train_data = vectorize_sequences(train_data) model = keras.Sequential([ layers.Dense(16, activation="relu"), layers.Dense(16, activation="relu"), layers.Dense(1, activation="sigmoid") ]) model.compile(optimizer="rmsprop", loss="binary_crossentropy", metrics=["accuracy"]) history_original = model.fit(train_data, train_labels, epochs=20, batch_size=512, validation_split=0.4)
Теперь попробуем заменить ее меньшей моделью.
Пример 5.11. Версия модели с меньшей емкостью
model = keras.Sequential([
layers.Dense(4, activation="relu"),
layers.Dense(4, activation="relu"),
layers.Dense(1, activation="sigmoid")
])
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
history_smaller_model = model.fit(
train_data, train_labels,
epochs=20, batch_size=512,
validation_split=0.4)
На рисунке 1 для сравнения показаны графики потерь на проверочных данных для исходной модели и ее уменьшенной версии.
import matplotlib.pyplot as plt orig = history_original.history["val_loss"] smaller = history_smaller_model.history["val_loss"] epochs = range(1, 21) plt.plot(epochs, orig, "b--", label="Потери исходной модели на проверочных данных") plt.plot(epochs, smaller, "b-", label="Потери уменьшенной модели на проверочных данных") plt.title("Сравнение потерь двух моделей") plt.xlabel("Эпохи") plt.ylabel("Потери") plt.legend()
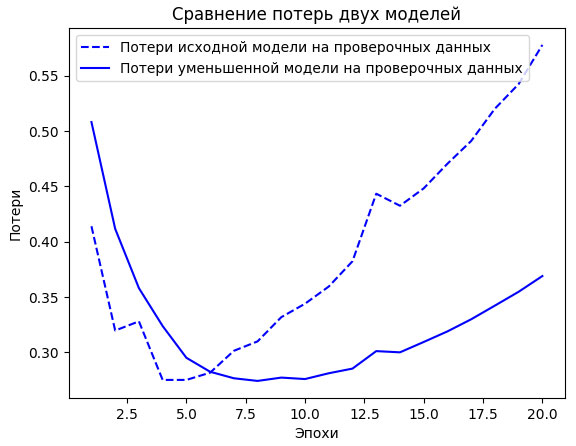
Рис.1. Сравнение оригинальной и уменьшенной моделей классификации отзывов в наборе данных IMDB
Как видите, эффект переобучения уменьшенной модели возникает позже, чем исходной (после шести эпох, а не четырех), и после начала переобучения ее качество ухудшается более плавно.
Теперь для контраста добавим сеть с большей емкостью - намного большей, чем необходимо для данной задачи.
В мире машинного обучения принято использовать модели, где количество параметров значительно превышает пространство признаков, которое они пытаются изучить, однако такие модели имеют слишком большую способность к запоминанию. Если модель слишком большая, она почти сразу же начнет переобучаться, а ее кривая потерь на проверочных данных будет выглядеть прерывистой с большой дисперсией (впрочем, большая дисперсия также может говорить о ненадежности процесса проверки, например если проверочная выборка слишком мала).
Приметр 5.12. Версия модели с намного большей емкостью
model = keras.Sequential([
layers.Dense(512, activation="relu"),
layers.Dense(512, activation="relu"),
layers.Dense(1, activation="sigmoid")
])
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
history_larger_model = model.fit(
train_data, train_labels,
epochs=20, batch_size=512, validation_split=0.4)
На рисунке 2 для сравнения приводятся графики потерь на проверочных данных для увеличенной и исходной моделей.
orig = history_original.history["val_loss"] larger = history_larger_model.history["val_loss"] epochs = range(1, 21) plt.plot(epochs, orig, "b--", label="Потери исходной модели на проверочных данных") plt.plot(epochs, larger, "b-", label="Потери увеличенной модели на проверочных данных") plt.title("Сравнение потерь двух моделей") plt.xlabel("Эпохи") plt.ylabel("Потери") plt.legend()
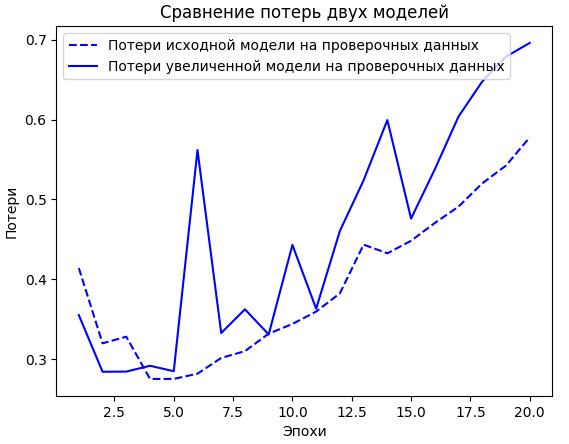
Рис.2. Сравнение оригинальной и увеличенной моделей классификации отзывов в наборе данных IMDB
Переобучение увеличенной модели наступает почти сразу же, после одной эпохи, и имеет намного более серьезные последствия. Кривая потерь на проверочных данных выглядит слишком искаженной. Большая модель быстро достигает нулевых потерь на обучающих данных. Чем больше емкость модели, тем быстрее она обучается представлять данные (что приводит к очень низким потерям на обучающих данных), но она более восприимчива к переобучению (что дает большую разность между потерями на обучающих и проверочных данных).
На следующем шаге мы рассмотрим добавление регуляризации весов.
