На этом шаге мы рассмотрим ее влияние на процесс обучения.
Возможно, вы знакомы с принципом бритвы Оккама: если какому-то явлению можно дать два объяснения, правильным, скорее всего, будет более простое - имеющее меньшее количество допущений. Эта идея применима также к моделям на основе нейронных сетей: для одних и тех же исходных условий - обучающей выборки и архитектуры сети - существует множество наборов весовых значений (моделей), объясняющих данные. Более простые модели менее склонны к переобучению, чем сложные.
Простая модель в данном контексте - это модель, в которой распределение значений параметров имеет меньшую энтропию (или модель с меньшим числом параметров, как было показано в предыдущих шагах). То есть типичный способ смягчения проблемы переобучения заключается в уменьшении сложности модели путем ограничения значений ее весовых коэффициентов, что делает их распределение более равномерным. Этот прием называется регуляризацией весов. Он реализуется добавлением в функцию потерь штрафа за увеличение весов и имеет две разновидности, такие как:
- L1-регуляризация (L1 regularization) - добавляемый штраф прямо пропорционален абсолютным значениям весовых коэффициентов (L1-норма весов);
- L2-регуляризация (L2 regularization) - добавляемый штраф пропорционален квадратам значений весовых коэффициентов (L2-норма весов).
В контексте нейронных сетей L2-регуляризация также называется сокращением весов (weight decay). Это два разных названия одного и
того же явления: сокращение весов с математической точки зрения есть то же самое, что L2-регуляризация.
В Keras регуляризация весов осуществляется путем передачи в слои именованных аргументов с экземплярами регуляризаторов весов. Рассмотрим пример добавления L2-регуляризации в сеть классификации отзывов о фильмах (пример 5.13).
Пример 5.13. Добавление L2-регуляризации весов в модель
from tensorflow.keras import regularizers model = keras.Sequential([ layers.Dense(16, kernel_regularizer=regularizers.l2(0.002), activation="relu"), layers.Dense(16, kernel_regularizer=regularizers.l2(0.002), activation="relu"), layers.Dense(1, activation="sigmoid") ]) model.compile(optimizer="rmsprop", loss="binary_crossentropy", metrics=["accuracy"]) history_l2_reg = model.fit( train_data, train_labels, epochs=20, batch_size=512, validation_split=0.4)
Блокнот с этим примером можно взять здесь.
Конструкция l2(0.002) означает, что каждый коэффициент в матрице весов слоя будет добавлять 0.002 * weight_coefficient_value ** 2 в общее значение потерь сети. Обратите внимание, что штраф добавляется только на этапе обучения, поэтому величина потерь сети на этапе обучения будет намного выше, чем на этапе контроля.
На рисунке 1 показано влияние L2-регуляризации. Как видите, модель с L2-регуляризацией намного устойчивее к переобучению, чем исходная, даже притом, что обе модели имеют одинаковое количество параметров.
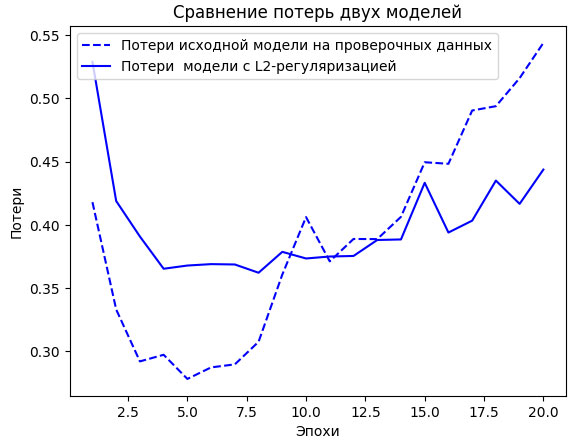
Рис.1. Влияние L2-регуляризации весов на величину потерь на проверочных данных
Вместо L2-регуляризации можно также использовать следующие регуляризаторы, входящие в состав Keras.
Пример 5.14. Разные регуляризаторы, доступные в Keras
from tensorflow.keras import regularizers regularizers.l1(0.001) # L1-регуляризация regularizers.l1_l2(l1=0.001, l2=0.001) # Объединенная L1- и 12-регуляризация
Обратите внимание, что регуляризация весов чаще применяется в небольших моделях глубокого обучения. Большие модели настолько чрезмерно параметризованы, что наложение ограничений на значения весов не оказывает большого влияния на способность модели к обобщению. В этих случаях предпочтительнее применять другой метод регуляризации - прореживание.
На следующем шаге мы рассмотрим прореживание.
