На этом шаге мы рассмотрим, то такое прореживание и как оно влияет на качество обучения.
Прореживание (dropout) - один из наиболее эффективных и распространенных приемов регуляризации нейронных сетей, разработанный Джеффом Хинтоном и его студентами в Университете Торонто. Прореживание, которое применяется к слою, заключается в удалении (присваивании нуля) случайно выбираемым признакам на этапе обучения. Представьте, что в процессе обучения некоторый слой для некоторого входного образца в нормальной ситуации возвращает вектор [0.2, 0.5, 1.3, 0.8, 1.1]. После прореживания некоторые элементы вектора получают нулевое значение: например, [0, 0.5, 1.3, 0, 1.1]. Коэффициент прореживания - это доля обнуляемых признаков; обычно он выбирается в диапазоне от 0,2 до 0,5. На этапе тестирования прореживание не производится; вместо этого выходные значения уровня уменьшаются на коэффициент, равный коэффициенту прореживания, чтобы компенсировать разницу в активности признаков на этапах тестирования и обучения.
Рассмотрим матрицу NumPy layer_output, полученную на выходе слоя, с формой (размер_пакета, признаки). На этапе обучения мы обнуляем случайно выбираемые значения в матрице:
# На этапе обучения обнуляется 50% признаков в выводе
layer_output *= np.random.randint(0, high=2, size=layer_output.shape)
На этапе тестирования мы уменьшаем результаты на коэффициент прореживания (в данном случае на 0,5, потому что прежде была отброшена половина признаков):
layer_output *= 0.5 # На этапе тестирования
Обратите внимание, что этот процесс можно реализовать полностью на этапе обучения и оставить без изменения результаты, получаемые на этапе тестирования, что часто и делается на практике (рисунок 1):
# На этапе обучения layer_output *= np.random.randint(0, high=2, size=layer_output.shape) # Обратите внимание: в данном случае происходит # увеличение, а не уменьшение значений layer_output /= 0.5
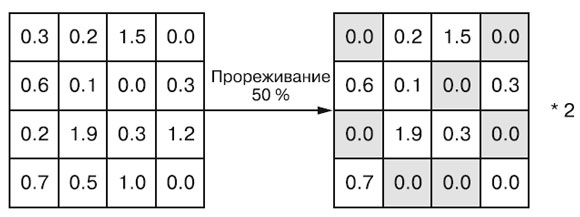
Рис.1. Прореживание применяется к матрице активации на этапе обучения с масштабированием на этом же этапе. На этапе тестирования матрица активации не изменяется
Этот прием может показаться странным и необоснованным. Каким образом он поможет справиться с переобучением? По словам Хинтона, основой для данного приема, кроме всего прочего, стал механизм, используемый банками для предотвращения мошенничества. Вот его слова: "Посещая свой банк, я заметил, что операционисты, обслуживающие меня, часто меняются. Я спросил одного из них, почему так происходит. Он сказал, что не знает, но им часто приходится переходить с места на место Я предположил, что это делается для исключения мошеннического сговора клиента с сотрудником банка. Это навело меня на мысль, что удаление случайно выбранного подмножества нейронов из каждого примера может помочь предотвратить заговор модели с исходными данными и тем самым ослабить эффект переобучения". Иными словами, основная идея заключается в введении шума в выходные значения, способного разбить случайно складывающиеся, не имеющие большого значения шаблоны (Хинтон называет их заговорами), которые модель начинает запоминать в отсутствие шума.
В Keras добавить прореживание можно введением в модель слоя Dropout, который обрабатывает результаты работы слоя, стоящего непосредственно перед ним. Давайте добавим два слоя Dropout в модель IMDB и посмотрим, как это повлияет на эффект переобучения.
Пример 5.15. Добавление прореживания в модель IMDB
model = keras.Sequential([
layers.Dense(16, activation="relu"),
layers.Dropout(0.5),
layers.Dense(16, activation="relu"),
layers.Dropout(0.5),
layers.Dense(1, activation="sigmoid")
])
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
history_dropout = model.fit(
train_data, train_labels,
epochs=20, batch_size=512, validation_split=0.4)
Блокнот с этим примером можно взять здесь.
На рисунке 2 показаны графики с результатами. И снова в сравнении с исходной моделью наблюдается улучшение .
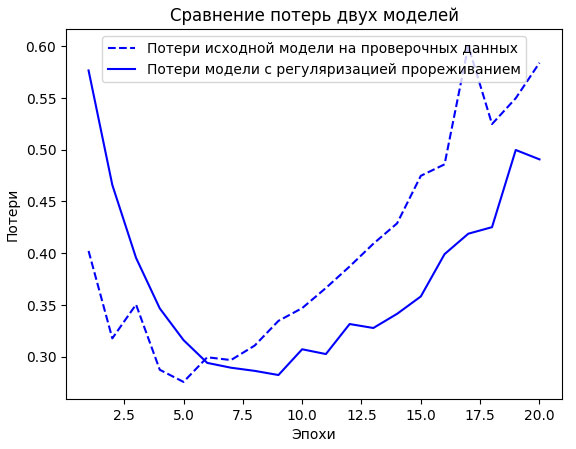
Рис.2. Влияние прореживания на величину потерь на проверочных данных
Таким образом, наиболее распространенные способы ослабления проблемы переобучения нейронных сетей следующие:
- увеличить объем обучающих данных и их качество;
- выбрать наиболее информативные признаки;
- уменьшить емкость сети;
- добавить регуляризацию весов (при использовании небольших моделей);
- добавить прореживание.
На следующем шаге мы подведем итоги по изученному материалу.
