На этом шаге мы рассмотрим работу этой функции.
Функция tokenize_unary() очень похожа на tokenize(). Но есть два важных отличия. Во-первых, если в первой позиции строки появляется символ "пробел", то функция вызывает саму себя (строка 7 примера 9.7), так как вслед за первой лексемой строки может оказаться унарный минус.
Во-вторых, если первый символ - знак минус, то он может быть только унарной операцией. А если он предшествует числу, то он становится частью этого числа, как будто бы это была цифра. Рассмотрим следующую схему:
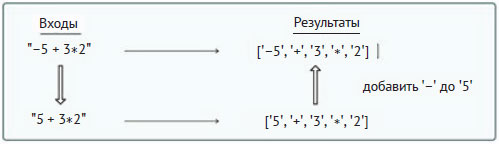
Отметим, что '-' добавляется к '5', чтобы получить лексему '-5'. Поэтому в строке 8 примера 9.7 проверяется, что s0 - знак минус, а строки 12-20 примера 9.7 идентичны строкам 40-48 примера 9.7.
Наконец, между строками 9 и 37 примера 9.7 тоже есть тонкое различие. Если вслед за цифрой идёт символ пропуска, то эта цифра становится лексемой (строки 9, 10 примера 9.7). Если же после унарного минуса идут пропуски, то это вовсе не значит, что он будет лексемой. Например, для строки "-6" алгоритм должен вернуть именно лексему '-6', а не две лексемы для каждого непустого символа. Таким образом, первое условие в строке 9 примера 9.7 до перехода к строке 10 примера 9.7, где создаётся лексема, проверяет, что символ - именно цифра. Наконец, при обработке строк, подобных "-6", рекурсивный вызов в строке 12 примера 9.7, игнорируя пропуски, возвращает лексему '6'. Таким образом, код в строке 17 примера 9.7 продолжает работу и правильно применяет унарный минус к 6, как будто бы он является цифрой.
На следующем шаге мы рассмотрим синтаксический анализатор на основе рекурсивного спуска.
