На этом шаге мы разберем принципы работы создаваемого синтаксического анализатора.
Создав список лексем, мы готовы обработать его, чтобы вычислить исходное математическое выражение. Конечно, лексемы не могут появляться в случайном порядке (например, в списке лексем не может быть двух подряд операций или чисел, незакрытых скобок и т. д.). Они должны подчиняться порождающим правилам формальной грамматики, описывающим правильный порядок следования лексем. Грубо говоря, порождающие правила нужны для того, чтобы сгруппировать лексемы или разложить список лексем на фрагменты, соответствующие определённым грамматическим категориям, и выстроить их иерархию.
Для нашего калькулятора такими категориями будут "Выражение" (Expression), "Слагаемое" (Term), "Множитель" (Factor) и несколько других, которые мы вкратце опишем. Чтобы понять эту идею, рассмотрим следующее математическое выражение:
-(2 + 3) + 2 * 8 / 4 - 3 * (4 + 2) / 6 + 7 - (-(2 + 8) * 3).
На рисунке 1 показано, что оно состоит из пяти слагаемых, связанных бинарными операциями плюс или минус.
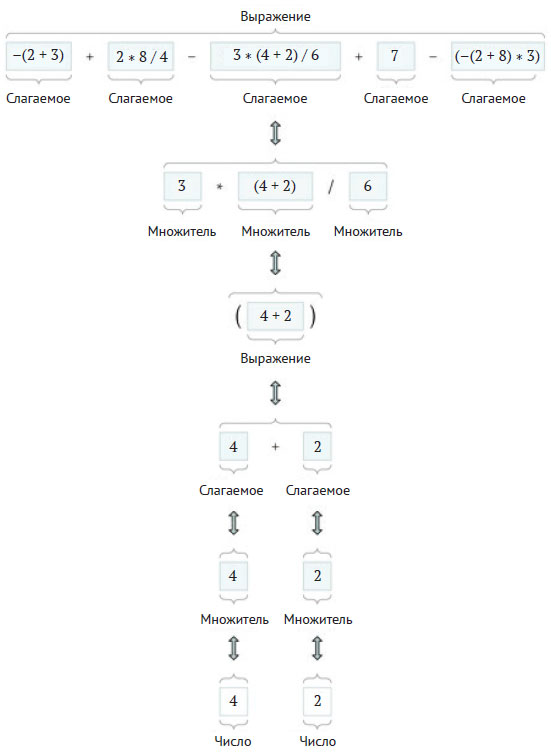
Рис.1. Декомпозиция математической формулы на категории "Выражение", "Слагаемое", "Множитель" или "Число"
Затем эти слагаемые могут быть разбиты на множители, связанные операциями '*' или '/'. На рисунке показано только разбиение слагаемого 3 * (4 + 2) / 6 на три множителя. Важно отметить, что второй множитель не является слагаемым исходного выражения, так как он заключён в круглые скобки. Кроме того, первый минус в выражении - унарный и, конечно же, не разделяет слагаемые. Унарный минус может также оказаться между двумя левыми круглыми скобками, как в последнем слагаемом.
Из рисунка видно, что множитель может быть выражением, заключённым в круглые скобки ("скобочным выражением"). Это значит, что определения выражения, слагаемого и множителя взаимно-рекурсивны. Обратите внимание, что выражение - это последовательность слагаемых, слагаемое - это ряд множителей, а множителем может быть или число, или другое скобочное выражение. Понятно, что и выражение, и слагаемое, и множитель могут быть просто числами.
Рассмотрим определение выражения с рекурсивной точки зрения. Его "размером" можно считать количество его слагаемых. Его начальное условие выполняется, когда оно состоит из единственного слагаемого. Но если в нём более одного слагаемого, то размер такого рекурсивного объекта можно уменьшить на 1 и определить его как подвыражение плюс/минус слагаемое. Такое рекурсивное определение в точности соответствует порождающим правилам формальной грамматики. Если E обозначает выражение, а T - слагаемое, то порождающие правила для выражения могут быть записаны с использованием следующей нотации:
E → T | E + T | E - T , (9.9)
E → T,
E → E + T и
E → E - T .
Однако для калькулятора, который мы хотим реализовать, не достаточно лишь одного определения выражения (9.9). В частности, есть ещё одно начальное условие для слагаемого, которое начинается с унарного минуса, продолжается скобочным выражением и заканчивается несколькими множителями. Пусть I - это то же самое слагаемое, но с противоположным (после применения унарной операции) знаком. Тогда порождающие правила для E будут такими:
E → T | E + T | E - T | -I . (9.10)
Таким же образом можно построить рекурсивные (или нерекурсивные) определения и для других элементов языка. Пусть F - множитель, P - скобочное выражение, а Number - числовая лексема, тогда полное описание грамматики, которую мы будем использовать:
E → T | E + T | E - T | -I
T → F | T * F | T / F
I → P | P * T | P / T
F → P | Number
P → (E)
Синтаксический анализатор на основе рекурсивного спуска - это программа проверки списка лексем на соответствие порождающим правилам грамматики, реализованным методами, которые обычно взаимно-рекурсивны. Обычно в таких анализаторах один метод соответствует одному символу (синтаксической переменной) в левой части порождающих правил, который предполагает, что входной список лексем имеет тип, определённый этим символом. Для нашего калькулятора мы построим синтаксический анализатор на основе рекурсивного спуска с пятью взаимно-рекурсивными функциями для каждого из символов E, T, I, F и P (на рисунке 2 приводятся взаимные вызовы методов).
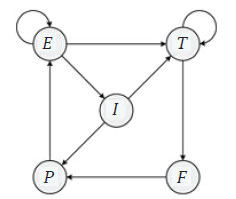
Рис.2. Взаимно-рекурсивные вызовы функций синтаксического анализатора на основе рекурсивного спуска
Например, соответствующая E функция обрабатывает выражения в предположении, что входной список лексем - именно выражение. В следующих шагах приводятся возможные реализации этих функций.
На следующем шаге мы рассмотрим функцию expression().
