На этом шаге мы перечислим эти недостатки.
Даже если вы знаете "правильное" количество кластеров для конкретного набора данных, алгоритм k-средних не всегда может выделить их. Каждый кластер определяется исключительно его центром, это означает, что каждый кластер имеет выпуклую форму. В результате этого алгоритм k-средних может описать относительно простые формы. Кроме того, алгоритм k-средних предполагает, что все кластеры в определенном смысле имеют одинаковый "диаметр", он всегда проводит границу между кластерами так, чтобы она проходила точно посередине между центрами кластеров. Это иногда может привести к неожиданным результатам, как показано на рисунке 1:
[In 53]: X_varied, y_varied = make_blobs(n_samples=200, cluster_std=[1.0, 2.5, 0.5], random_state=170) y_pred = KMeans(n_clusters=3, random_state=0).fit_predict(X_varied) mglearn.discrete_scatter(X_varied[:, 0], X_varied[:, 1], y_pred) plt.legend(["кластер 0", "кластер 1", "кластер 2"], loc='best') plt.xlabel("Признак 0") plt.ylabel("Признак 1")
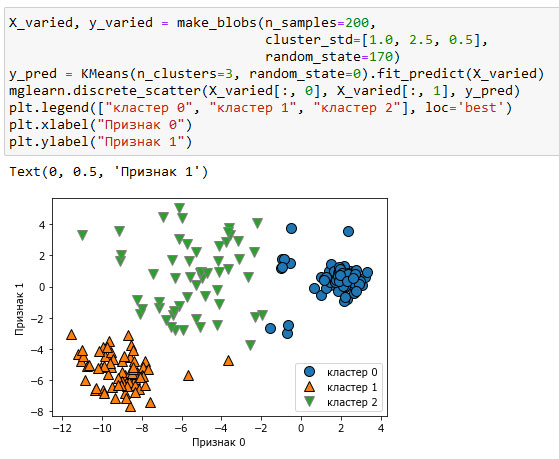
Рис.1. Принадлежность к кластерам, найденная с помощью алгоритма k-средних, при этом кластеры имеют разные плотности
Можно было бы ожидать плотную область в нижнем левом углу, которая рассматривалась бы в качестве первого кластера, плотную область в верхнем правом углу в качестве второго кластера и менее плотную область в центре в качестве третьего кластера. Вместо этого, у кластера 0 и кластера 1 есть несколько точек, которые сильно удалены от всех остальных точек этих кластеров, "тянущихся" к центру.
Кроме того, алгоритм k-средних предполагает, что все направления одинаково важны для каждого кластера. Следующий график (рисунок 2) показывает двумерный набор данных с тремя четко обособленными группами данных. Однако эти группы вытянуты по диагонали. Поскольку алгоритм k-средних учитывает лишь расстояние до ближайшего центра кластера, он не может обработать данные такого рода:
[In 54]: # генерируем случайным образом данные для кластеризации X, y = make_blobs(random_state=170, n_samples=600) rng = np.random.RandomState(74) # преобразуем данные так, чтобы они были вытянуты по диагонали transformation = rng.normal(size=(2, 2)) X = np.dot(X, transformation) # группируем данные в три кластера kmeans = KMeans(n_clusters=3) kmeans.fit(X) y_pred = kmeans.predict(X) # строим график принадлежности к кластерам и центров кластеров plt.scatter(X[:, 0], X[:, 1], c=y_pred, cmap=mglearn.cm3) plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], marker='^', c=[0, 1, 2], s=100, linewidth=2, cmap=mglearn.cm3) plt.xlabel("Признак 0") plt.ylabel("Признак 1")
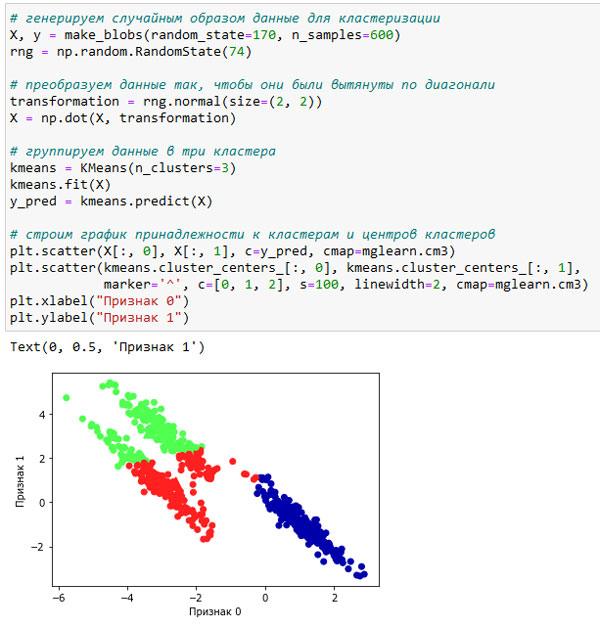
Рис.2. Алгоритм k-средних не позволяет выявить несферические кластеры
Кроме того, алгоритм k-средних плохо работает, когда кластеры имеют более сложную форму, как в случае с данными two_moons, с которыми мы сталкивались ранее (см. рисунок 3):
[In 55]: # генерируем синтетические данные two_moons # (на этот раз с меньшим количеством шума) from sklearn.datasets import make_moons X, y = make_moons(n_samples=200, noise=0.05, random_state=0) # группируем данные в два кластера kmeans = KMeans(n_clusters=2) kmeans.fit(X) y_pred = kmeans.predict(X) # строим график принадлежности к кластерам и центров кластеров plt.scatter(X[:, 0], X[:, 1], c=y_pred, cmap=mglearn.cm2, s=60) plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], marker='^', c=[mglearn.cm2(0), mglearn.cm2(1)], s=100, linewidth=2) plt.xlabel("Признак 0") plt.ylabel("Признак 1")
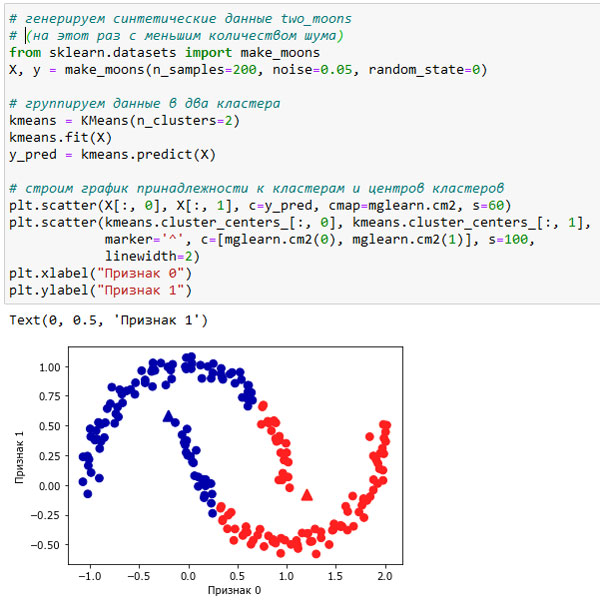
Рис.3. Алгоритм k-средних не позволяет выявить кластеры более сложной формы
В данном случае мы понадеялись на то, что алгоритм кластеризации сможет обнаружить два кластера в форме полумесяцев. Однако определить их с помощью алгоритма k-средних не представляется возможным.
На следующем шаге мы рассмотрим векторное квантование.
