На этом шаге мы рассмотрим правила конструирования признаков.
Еще один способ обогатить пространство признаков, в частности, для линейных моделей, заключается в добавлении взаимодействии признаков (interaction features) и полиномиальных признаков (polynomial features). Конструирование признаков подобного рода получило распространение в статистическом моделировании, а также широко используется во многих практических сферах применения машинного обучения.
Для начала снова посмотрите на рисунок 2 предыдущего шага. Для каждой категории признака линейная модель предсказывает одно и то же значение. Однако мы знаем, что линейные модели могут вычислить не только значения сдвига, но и значения наклона. Один из способов добавить наклон в линейную модель, построенную на основе категоризированных данных, заключается в том, чтобы добавить обратно исходный признак (ось х на графике). Это приведет к получению 11-мерного массива данных, как показано на рисунке 1:
[In 17]: X_combined = np.hstack([X, X_binned]) print(X_combined.shape) (100, 11)
[In 18]: reg = LinearRegression().fit(X_combined, y) line_combined = np.hstack([line, line_binned]) plt.plot(line, reg.predict(line_combined), label='линейная регрессия после комбинирования') for bin in bins: plt.plot([bin, bin], [-3, 3], ':', c='k') plt.legend(loc="best") plt.ylabel("Выход регрессии") plt.xlabel("Входной признак") plt.plot(X[:, 0], y, 'o', c='k')
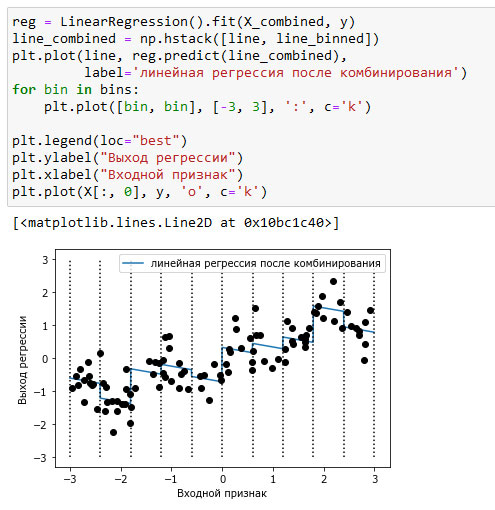
Рис.1. Линейная регрессия с использованием категоризированных признаков и одним глобальным наклоном
В этом примере модель вычислила сдвиг для каждой категории, а также наклон. Вычисленный наклон направлен вниз и он является общим для всех категорий, так как у нас имеется толька один признак по оси x с одним коэффициентом. Поскольку наличие одного наклона для всех категорий не очень сильно поможет с точки зрения моделирования, мы бы хотели вычислить для каждой категории свой собственный наклон! Мы можем добиться этого, добавив взаимодействие или произведение признаков, указывающее категорию точки данных и ее расположение на оси х. Данный признак является произведением индикатора категории и исходной переменной. Давайте создадим этот набор данных:
[In 19]: X_product = np.hstack([X_binned, X * X_binned]) print(X_product.shape) (100, 20)
Теперь набор данных содержит 20 признаков: в него записывается индикатор категории, в которой находится точка данных, а также произведение исходного признака и индикатора категории. Произведение признаков можно представить как отдельную копию признака, отложенного по оси х, для каждой категории. Оно соответствует исходному признаку, попадающему в данную категорию, или нулю во всех остальных случаях. На рисунке 2 показан результат линейной модели для этого нового пространства признаков:
[In 20]: reg = LinearRegression().fit(X_product, y) line_product = np.hstack([line_binned, line * line_binned]) plt.plot(line, reg.predict(line_product), label='линейная регрессия произведение') for bin in bins: plt.plot([bin, bin], [-3, 3], ':', c='k') plt.plot(X[:, 0], y, 'o', c='k') plt.ylabel("Выход регрессии") plt.xlabel("Входной признак") plt.legend(loc="best")
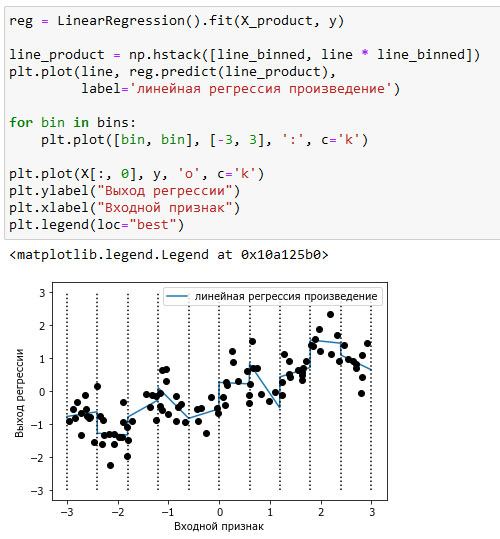
Рис.2. Линейная регрессия с отдельным наклоном для каждой категории
Видно, что теперь каждая категория имеет свое собственное значение сдвига и свое собственное значение наклона.
На следующем шаге мы продолжим изучение этого вопроса.
