На этом шаге мы рассмотрим пример таких данных.
В реальных наборах данных довольно часто некоторые входные данные оказываются искаженными. Например, изображение цифры в наборе MNIST может не содержать ничего, кроме черных пикселей, или выглядеть необычно (рисунок 1).

Рис.1. Некоторые необычные образцы в обучающей выборке в наборе MNIST
Что это за цифры? Однако все они присутствуют в обучающей выборке в наборе MNIST. Но это полбеды. Что еще хуже, так это наличие совершенно правильных входных данных, которые имеют ошибочные метки (рисунок 2).

Рис.2. Образцы в обучающей выборке в наборе MNIST, имеющие неверные метки
Если модель постарается учесть такие выбросы, ее способность к обобщению ухудшится (рисунок 3).
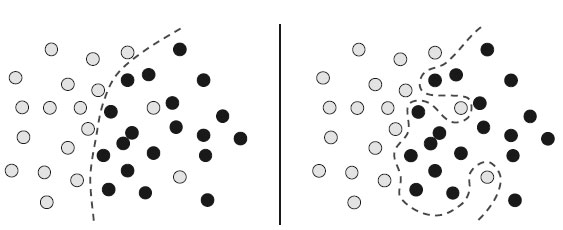
Рис.3. Обобщение выбросов: надежное обучение против переобучения
Например, рукописная цифра 4, которая очень похожа на 4 с ошибочной меткой на рисунке 2, может в конечном итоге классифицироваться как 9.
На следующем шаге мы рассмотрим неоднозначные признаки .
