На этом шаге мы рассмотрим, что понимается под неопределенными признаками.
Не всякий шум в данных возникает из-за неточностей - даже идеально отобранные и аккуратно промаркированные данные могут быть зашумлены, когда имеет место неопределенность и неоднозначность. В задачах классификации часто бывает так, что некоторые области пространства исходных признаков связаны сразу с несколькими классами. Представьте, что вы разрабатываете модель, которая по изображению банана предсказывает - является он незрелым, спелым или гнилым. Эти категории не имеют объективных границ, поэтому одно и то же изображение может быть классифицировано разными людьми как изображение незрелого или спелого банана. Аналогично многие задачи связаны со случайностью. Например, вы могли бы взяться за предсказание дождя по атмосферному давлению, но за одинаковыми измерениями с некоторой вероятностью иногда следует дождливая, а иногда солнечная погода.
Модель могла бы переобучиться - запомнить такие вероятностные данные в обучающей выборке, игнорируя возможность присутствия областей неопределенности в пространстве признаков (рисунок 1).
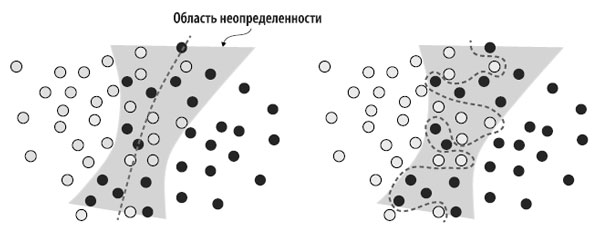
Рис.1. Надежно обученная и переобученная модели по-разному видят область неопределенности в пространстве признаков
На уровне надежного обучения модель способна игнорировать отдельные образцы и видеть картину в целом.
На следующем шаге мы рассмотрим, что такое редкие признаки и ложная корреляция.
